
Gordon Rugg's Blog
December 22, 2023
Syndromes and permutations
By Jennifer Skillen, Gordon Rugg and Sue Gerrard
Some diagnoses are clear and simple, and give you a crisp either/or categorisation; either the case in question has a positive diagnosis, or it doesn’t. Diagnosis involves identification of the cause of a problem; this may occur in medicine, or in mechanical fault finding, or in other fields. This article focuses on medicine, but the concepts involved are relevant to diagnosis in other fields.
The diagram below shows crisp either/or diagnosis visually; cases either go in box A or box B, with no other options.

Not all diagnoses are this simple. Medical syndromes are an example. A syndrome in the medical sense involves a pattern of features that tend to co-occur, but where the cause is unknown. They typically involve multiple signs and symptoms, each of which may or may not be present in a particular case. (Signs are features that can be observed by someone other than the patient; symptoms can only be observed by the patient.) Making sense of syndromes, and of how to diagnose syndromes, is difficult, and often encounters problems with misunderstandings and miscommunications.
This article discusses ways of defining syndromes and related issues. Its main focus is on medical diagnosis, but the same principles apply to problems in other fields that have the same underlying deep structure.
Some cases involve a greyscale, such as the one shown below, rather than a crisp division into clear-cut categories, as shown in the “A or B” example above.

An example of a greyscale might be the severity of a fracture, ranging from very severe at one end of the scale, to minor at the other.
It’s often possible for a case to involve more than one form of categorisation. For instance, a particular fracture might be described both by its category (e.g. compound versus simple) and its severity (e.g. very severe to minor).
It’s also possible for a diagnosis to involve a combination of crisp and fuzzy sets, as shown below. In this diagram, some cases are definitely A; some are definitely B; others are on a greyscale between A and B. Using the fracture example again, it’s possible to think of greenstick fractures (C) as fitting on a greyscale between completely fractured (A) and not fractured at all (B).

An advantage of using diagrams in this way is that many people find them easier to understand than verbal descriptions, which can help communication.
In the examples above, the diagnosis involves a single condition with a known cause which definitely exists in the world. However, syndromes are more conceptually complex. They have unknown causes, and typically involve several different diagnostic features, which may not all be present.
This means that there is a risk of reification, i.e. a risk of inventing something which doesn’t exist in the real world. The pair of images below show how this can happen.
In the image below, Syndrome X may be caused by A, and/or B and/or C, and leads to outcomes 1 and/or 2, and/or 3.

However, in the next image, the same causes and outcomes are mapped directly onto each other, without using an intermediate Syndrome X. In this mapping, not all causes lead to all outcomes; Cause A, for instance, leads to Outcome 1 and Outcome 3, but not to Outcome 2.

The first of the two images above uses a syndrome as part of the causal modelling between causes and outcomes; the second models the same set of causes and outcomes without using a syndrome. Both handle the same evidence. So, how does involving a syndrome help make sense of what’s going on?
One key feature of a proposed syndrome is that it involves features that co-occur at above chance levels, for whatever reason. If you are sure that Syndrome X is present, and you’ve already seen Outcome 1 and Outcome 2 in a given case, then you know to check for Outcome 3 as well, and to be ready for it if it isn’t already present.
However, there is the risk of clusters of correlations occurring just by chance, or because of other factors that don’t actually justify invoking a syndrome (e.g. co-morbidity, or a shared deeper cause for two features). A possible example is Gerstmann Syndrome, which involves several loosely related problems, such as inability to distinguish the fingers on the hand from each other. There is debate in the literature about whether there is any medical advantage in treating these problems as a syndrome.
One way of representing the problem more systematically is to use a representation that shows all the logically possible permutations for a given set off diagnostic signs and symptoms, as shown below. This format is described in more detail in Skillen (2017). On the left, in Column A, all four are present. The next four columns show the different ways in which three of the four can be present. The following six columns show the different ways in which two of the four can be present, and the final four columns show each attribute occurring on its own.

With this representation, it’s possible to show how often each permutation occurs. For instance, Permutation B (Attributes 1, 2 and 3 together) might be much more common than Permutation C or Permutation D, but all three of those permutations might occur at levels well above chance. This provides a finer-grained way of handling syndromes than a simple binary “either the syndrome is present or it isn’t” diagnosis. Differences in frequency of occurrence of permutations would help identify different sub-groups of people within the syndrome, or different versions of the syndrome; occurrence of a permutation at above chance levels would support the argument that there is a real syndrome, rather than just a coincidence.
So, in summary, using systematic representations can help clarify terminology and definitions relating to syndromes and similar concepts.
Notes and links
https://en.wikipedia.org/wiki/Gerstmann_syndrome
Skillen, J.D., 2017. The symptom matrix: Using a formalism‐based approach to address complex syndromes systematically. Musculoskeletal Care, 15(3), pp.253-256.
https://onlinelibrary.wiley.com/doi/abs/10.1002/msc.1168
Jennifer Skillen can be contacted at her Keele University email address: j.d.skillen@keele.ac.uk
Gordon Rugg and Sue Gerrard can be contacted at Hyde & Rugg: gordon@hydeandrugg.com
Other resources that you may find useful:
The Hyde & Rugg website contains material relating to ways of handling knowledge, including elicitation, representation, testing/error and education.
The Hyde & Rugg blog contains articles that discuss concepts and methods for handling knowledge.
The Knowledge Modelling Handbook covers a wide range of concepts and representations, including the ones in this article.
Gordon Rugg & Joe D’Agnese’s book, Blind Spot tells the story of our work on identifying and reducing error in expert reasoning about difficult problems:
The Unwritten Rules of PhD Research, by Gordon Rugg and Marian Petre, is a book written to help PhD students understand the world of research, and how to survive and do well in it.


December 4, 2023
Artificial Intelligence and reality
By Gordon Rugg
There’s a lot of talk about Artificial Intelligence (AI) at the moment, usually framed in either/or terms. For anyone who worked with AI in the 1980s, this is depressingly familiar.
The brief version is that yes, AI will bring massive changes in some areas but not in the ways that most people are claiming, and no, it won’t bring massive changes in others that most people are worried about, and by the way, there are a lot of really useful things that it could be doing, but that have been marginalised or ignored or unknown for over forty years.
So, what’s the reality about AI?
The type of AI getting most attention at the moment involves a glorified version of predictive text. The AI knows which statements are most likely to follow a given initial statement, based on a huge corpus of text that acts as the source for those likelihoods (e.g. “In these 3 million exchanges on Twitter/X, this phrase followed that phrase on 231 occasions”). The full story is more complicated; for instance, you need some heavy duty grammatical rules to join the phrases together coherently, and you need ways of assessing which pieces of text to ignore. The core principle, though, is using correlations to string chunks of text together.
That’s the same underlying principle as the “Customers who bought this also bought that” approach, and it has the same strengths and weaknesses. When things go well, this principle can identify real correlations, including correlations that humans had missed. When things don’t go so well, it can identify real correlations, but in a way that completely misses the point. A common example in online shopping occurs when someone buys a gift for the legendary crazy uncle, and then buys themselves a reward that’s much more aligned with their own preferences. That’s how you can get recommendations like “Customers who bought Max Bygraves’ Greatest Hits also bought Soothing Nature Music”.
When things go badly, you can end up with results that are dangerously wrong. That’s bad enough on its own, but it’s doubly bad when the results look highly plausible.
Plausible but wrong results usually occur because the AI is just joining strings of letters together, without any understanding of what they actually mean. It’s a phenomenon that’s horribly familiar to anyone who has worked in education for a while. There’s a type of student that is very good at stringing together relevant buzzwords in a way that sounds initially plausible. Where it all goes wrong is when you ask them to apply what they’ve just said to a real problem. With students, you see a blank stare in some cases, and a look of horror in others, depending on whether or not they’re aware of why their knowledge isn’t joined up to the real world. That’s why I used extended case studies in my teaching, to make students apply what they were learning to real problems, and check that they really understand it.
This is why a lot of boring technical details are really, really important when setting up and using an AI system. If it’s getting its chunks of phrasing from the unfiltered Internet, for instance, then asking the AI who built the pyramids is likely to generate some very strange answers indeed. Even when you’re using text from peer-reviewed papers as your input for the AI, there’s no guarantee that their content will be okay; in fact, a key issue when human researchers do a proper survey of the literature on a topic involves critical assessment of that literature, not just repeating what was said within that literature. Incidentally, this is a significant problem with a lot of so-callled Systematic Literature Reviews; I’ve seen some appalling examples which were worse than useless, because they misunderstood key points in the texts that they were reviewing, and produced results that looked very plausible and scientific, but were actually profoundly wrong.
So, what is likely to happen with predictive text AI?
It will probably produce drastic changes in some fields that involve summarising and/or generating text. Examples include journalism and copy writing for routine copy. A key variable is whether the field involves significant risk of major legal action. If your AI generated text produces an unreliable claim in some advertising copy for a new type of coffee maker, then there’s not much risk of serious consequences. If, however, your AI generated text makes an error in a key point in an assessment of a medical procedure or a safety-critical software design, then the legal consequences could be very serious indeed. So, there’s a good chance that various fields will use AI to replace some of their staff, and a good chance that some of those fields will later seriously regret it and go back to the old ways.
What probably won’t happen is that predictive AI will be very efficient at generating new knowledge by stringing together bits of the existing literature. Yes, it will produce some new insights and associations, but those will need to be checked by a human in case they’re just coincidental. If you want to generate new insights and new knowledge, there are far more efficient ways of doing it by using other AI approaches.
Similarly, predictive text AI is unlikely to make all humans redundant. It does one thing very plausibly, and does it reasonably well most of the time, but most jobs don’t consist only of that one thing. Likewise, predictive text AI won’t turn into Skynet and obliterate us in a nuclear catastrophe; worrying about that risk is like worrying about whether your word processing package will make your household appliances try to kill you.
What depresses me about predictive text AI is the mediocrity of the claims about how it will be used. Yes, it will probably produce better chatbots. Yes, it will probably produce summaries of text, and answers to questions, that are as good as you’d get from a competent new hire. What gets me is the missed opportunities. Chatbots and text summarising might make short-term commercial sense, but they’re not likely to make many lives significantly better.
The key discoveries about AI were pretty well established forty years ago. Types of AI such as Artificial Neural Nets (ANNs) and genetic algorithms (GAs) and specialist systems emulating human expertise were all out-performing human experts in specialised tasks forty years ago. Instead of being taken up as powerful tools to support human experts, these technologies were largely used either for unglamorous low-level tasks such as optimising engine performance, or viewed as possible alternatives to human experts (and therefore as potential threats). There was far less interest in systematically identifying ways for humans and AI to work together on extending human creativity, or solving hard research problems, or generally making the world better.
That leads into the concept of task partitioning, which is about systematically breaking a task down into sub-tasks, and then allocating those sub-tasks to whichever route (human, AI, other software, hardware) is most suitable. This will be the topic of a future article.
Notes and links
You’re welcome to use Hyde & Rugg copyleft images for any non-commercial purpose, including lectures, provided that you state that they’re copyleft Hyde & Rugg.
You might also find our website useful: https://www.hydeandrugg.com/
September 13, 2023
User-centred grammar
By Gordon Rugg
Within linguistics, the scientific study of language, there is a long-established and useful distinction between two approaches to grammar, namely prescriptive grammar and descriptive grammar. This article describes a third approach, namely user-centred grammar. Before describing this third approach, I’ll briefly summarise the other two.
Background
Prescriptive grammar typically takes the view that there is a “correct” form of grammar for a dialect or language that should be followed by everyone, including people for whom that dialect or language is their native tongue. An example from Standard English is the claim that one should say “It is I” as opposed to “It is me”. Similarly, prescriptive grammar often makes normative claims about correctness based on claims that a particular phrasing is in some sense logically correct. An example in English is how to treat two negatives (e.g. “I haven’t got nothing”). Prescriptive grammar typically claims that these should cancel each other out because that is “logical” by analogy with formal logic.
Descriptive grammar describes the grammar used by native speakers of a dialect or language, without any normative claims. For the first example above, the descriptive approach would say that some native speakers of Standard English say “It is I” but that most native speakers of English say “It is me”. For the second example above, descriptive grammar typically states that in various dialects of English, the two negatives are treated as reinforcing each other.
Historically, prescriptive grammar has tended to invoke semi-arbitrary norms based on the grammar of other languages that have high status. In the case of Standard English, for example, prescriptive grammar frequently invoked norms from Latin (“we should use this phrasing in English because that’s what Latin would do”).
The use of descriptive grammar in linguistics has numerous advantages in terms of internal consistency, of avoiding imposition of arbitrary and semi-arbitrary norms on native speakers of a language, and of avoiding the social stigmatisation of dialects and languages other than the most prestigious ones. However, there are situations where phrasings can make a significant difference in how well a person can communicate their intended message to others. This causes problems for anyone attempting to teach ways of avoiding unintended consequences from particular phrasings, because this can look like an attempt to impose subjective norms.
The approach described in this article, namely user-centred grammar, provides a possible way of resolving this apparent paradox.
User-centred approaches
User-centred approaches are widely used in design, particularly design of software systems. The core concepts involve identifying and incorporating design features that will make the system easier to use, while identifying and eliminating design features that will make the system more difficult to use. A key point is that the concepts of “easy to use” and “difficult to use” are defined and measured using objective features, such as the number of actions that a user needs to perform in order to complete a specific task. For instance, software systems with very large numbers of users, such as those selling products online, are designed to minimise the number of mouse clicks involved in making a purchase, because each extra click costs time and money, and also significantly increases the likelihood that a user will give up and leave the site.
User-centred grammar
User-centred grammar aims to make text easier for the user to parse, by reducing the number of cognitive steps required to interpret a statement into the meaning intended by the person who produced that sentence.
For example, the phrase “old men and women” can be parsed either as “old men and old women” or as “old men, and women of any age”. This means that the reader cannot be sure what the intended meaning is.
This type of ambiguity is sometimes resolved by the wording later in a sentence. An example is: “Old men and women suffer problems that do not affect young people”. This context makes it clear that the intended meaning is old men and old women. However, this phrasing means that the reader/listener has to hold both possible meanings in memory until they reach the disambiguating phrase, causing unnecessary extra mental load.
Using a different phrasing, such as: “Old men and old women suffer problems that do not affect young people” means that the reader/listener can parse the sentence in the intended sense on the first pass, with less mental load.
Concepts from user-centred design provide a more rigorous foundation than traditional prescriptive grammar or descriptive grammar, for providing guidance on writing in a way that is more easily and accurately parsed, in a way that is based on relatively objective measures.
Well-recognised causes of parsing problems include:
uncertainty about which nouns in a list are being described by a previous adjective (as in the “old men and women” example)
uncertainty about the relationship between two words or phrases at the end of a list (the Oxford comma problem)
anaphoric reference (e.g. “He handed him his pen” where “his” could refer back either to the first or the second person mentioned)
cataphoric reference (e.g. “After leaving her house, she waved goodbye to her friend” where the first “her” could refer forward either to “she” or “her friend”).
A related issue both for prescriptive and descriptive language is language change. Scientific writing is explicitly intended to be understandable with the minimum of effort by future researchers. This is one reason that scientific writing deliberately doesn’t use fashionable or regional slang in an attempt to be more interesting or accessible. An example is slang use of “bomb” in popular English, where “it’s the bomb” means that the thing is excellent, but “it’s a bomb” means that the thing is a failure. These slang meanings will probably be forgotten within a few years, whereas “excellent” and “failure” will probably still have much the same meaning in a century. Again, a user-centred approach provides a non-judgmental basis for language choice.
Other issues
There are various other issues in guidance about phrasing and language choice which can also be usefully viewed from a user-centred perspective.
Grey scales in user centred grammar
The examples above mainly involve crisp sets, where there are clearly distinct possible meanings. However, there are also ways of using user-centred grammar with fuzzy sets, where the issues involved are on a grey scale.
For instance, there are phrasings which signal to the reader that the writer has a sophisticated knowledge of a topic. In academic writing, examples include use of technical terms such as c.f. and references to advanced articles in specialist journals. Sophisticated knowledge forms a grey scale, rather than being an either/or binary choice; there are degrees of sophistication, and degrees to which the reader might understand the intended signals from such phrasings.
Similarly, the writer may use a phrasing that anticipates and resolves a possible question before the reader asks it; for instance, a phrasing that makes it clear that the writer didn’t make a slip of the pen when making an unlikely-looking assertion.
Deliberate vagueness
Popular articles about writing usually condemn vagueness. However, in some situations deliberate vagueness has advantages. In constructive politics and constructive negotiation, for instance, vague wording can give the parties room for manoeuvre, whereas precise wording early on could impose hard constraints before the options had been fully explored.
Allegedly, many of the political and legal agreements that patched together a peace after the English Civil War were deliberately vague about various issues because that vagueness allowed the relevant parties to move forward, without having to re-start the war to settle those issues. Several centuries later, that deliberate vagueness is still helping to keep the peace.
Legal implications
Particular phrasings may have significant legal implications; for instance, the difference between i.e. and e.g.
i.e. comes from Latin id est, meaning that is. e.g. is from Latin exampli gratia, meaning for the sake of example. If you use i.e. you are specifying which item or items you mean; if you use e.g. you are giving some examples. This can be a very significant distinction.
Expressive and instrumental language
Expressive behaviour is intended to show what sort of person one is; instrumental behaviour is intended to achieve a practical aim. An example of expressive behaviour is wearing a hat with the slogan of the political party that the wearer supports, to show political allegiance. An example of instrumental behaviour is wearing a safety helmet, to prevent injury. Some behaviour is both instrumental and expressive at the same time, such as a politician putting on a safety helmet during a factory visit to show solidarity with construction workers (expressive) while protecting their head (instrumental).
Expressive and instrumental behaviour can be shown via language. Much of the language in populist rhetoric involves use of words and phrases that signal group allegiance, where the demonstration of allegiance is treated as more important than the actual logical meaning of what is being said. Conversely, most of the language in legal documents and technical manuals is as instrumental as possible.
Some language is deliberately both instrumental and expressive. For example, a political speech writer may make a very deliberate, instrumental choice about whether to describe a group as freedom fighters, rebels, revolutionaries, or insurgents in a speech. Each of these implications has different implications politically and also legally (for instance, in terms of whether they can legally receive a particular type of aid).
We blogged HERE about the implications of expressive and instrumental behaviour and language for possible problems in interactions between patients and medical professionals.
Conclusion
Although the distinction between prescriptive grammar and descriptive grammar is useful in some contexts, it tends to be unhelpful in other contexts. This article is intended to show how a person can make choices between phrasings in a way that is neither arbitrarily normative, nor unhelpfully non-directive, and that ties in with practical issues in the world.
Notes and links
You’re welcome to use Hyde & Rugg copyleft images for any non-commercial purpose, including lectures, provided that you state that they’re copyleft Hyde & Rugg.
There’s more about the theory behind this article in my book Blind Spot, by Gordon Rugg with Joseph D’Agnese.
You might also find our website useful. We have recently updated the website, with a lot of new features, including a much expanded resource section.
September 13, 2022
It’s logic, Jim, but not as we know it: Associative networks and parallel processing
By Gordon Rugg
A recurrent theme in our blog articles is the distinction between explicit knowledge, semi-tacit knowledge and tacit knowledge. Another recurrent theme is human error, in various forms. In this article, we’ll look at how these two themes interact with each other, and at the implications for assessing whether or not someone is actually making an error. We’ll also re-examine traditional logic, and judgement and decision-making, and see how they make a different kind of sense in light of types of knowledge and mental processing. We’ll start with the different types of knowledge.
Explicit knowledge is fairly straightforward; it involves topics such as what today’s date is, or what the capital of France is, or what Batman’s sidekick is called. Semi-tacit knowledge is knowledge that you can access, but that doesn’t always come to mind when needed, for various reasons; for instance, when a name is on the tip of your tongue, and you can’t quite recall it, and then suddenly it pops into your head days later when you’re thinking about something else. Tacit knowledge in the strict sense is knowledge that you have in your head, but that you can’t access regardless of how hard you try; for instance, knowledge about most of the grammatical rules of your own language, where you can clearly use those rules at native-speaker proficiency level, but you can’t explicitly say what those rules are. Within each of these three types, there are several sub-types, which we’ve discussed elsewhere.
So why is it that we don’t know what’s going on in our own heads, and does it relate to the problems that human beings have when they try to make logical, rational decisions? This takes us into the mechanisms that the brain uses to tackle different types of task, and into the implications for how people do or should behave, and the implications for assessing human rationality.
What goes on in the head sometimes stays in the head
A key issue is that the human brain uses different approaches to tackle different types of problem. One approach involves the sort of explicit step-by-step reasoning that is taught in school maths and logic lessons. The other doesn’t. These approaches are very different from each other. The good news is that the differences complement each other, and allow us to tackle problems that would be difficult or impossible with one approach alone. The bad news is that the brain has cobbled the two together in ways that made evolutionary sense at the time, but that don’t seem quite such a good idea now.
In some fields, the two approaches are well recognised and well understood. In other fields, their effects are recognised but the underlying mechanisms and processes are not generally known. In psychology, for instance, Kahneman’s distinction between System 2 and System 1 thinking corresponds closely to these approaches, but his book Thinking Fast and Slow doesn’t mention two key underlying mechanisms by name. In most fields, however, these approaches are little known and their implications are not recognised.
I’ve used the word approach deliberately, as a broad umbrella term that covers various mechanisms, processes and representations, that tend to co-occur with each other but are conceptually separate.
I’ll begin by describing two key mechanisms, and then proceed to a description of the two approaches.
Serial processing and parallel processing
Two key mechanisms for understanding how the human brain works are serial processing and parallel processing. Serial processing involves proceeding via one action at a time. Parallel processing involves proceeding via two or more actions simultaneously. The images below show this distinction. It looks simple and trivial; in fact, it is simple in essence, but its implications are huge, and nowhere near as widely known as they should be.
Serial processing: One action at a time
Parallel processing: More than one action at a time

The distinction between serial and parallel processing is well understood in computing; it’s also routinely used in some fields such as project planning, where some parts of a project have to be done serially in sequence (e.g. first laying the foundations for a building, and then after that building the walls on those foundations) whereas other parts can be done in parallel (e.g. having several teams each building the walls on a different building on the same site at the same time).
Serial processing and parallel processing are closely linked with several other concepts, in particular explicit reasoning and crisp sets in the case of serial processing, and associative networks and pattern matching in the case of parallel processing. I’ll start by describing the combination of serial processing, explicit reasoning, and crisp sets, all of which will be familiar to most readers, even if they haven’t previously encountered those names for those concepts. I’ll look briefly at the obvious, well known limitations of each of these, and then look in more detail at some less obvious, less well known, limitations, whose implications have only become apparent within recent decades. That will set the stage for examining the combination of parallel processing, associative networks and pattern matching, which together can handle challenges that are difficult or impossible using the serial/explicit/crisp combination. I’ll then look at the implications of having both these approaches being used within the brain.
The serial processing/explicit reasoning/crisp set package
We’ll begin with a simple traditional example of how formal logic uses serial processing and explicit reasoning.
Socrates is a manAll men are mortalTherefore Socrates is mortalFormal logic has an extensive set of technical terms to describe this set of steps, but we’ll leave those to one side, and focus instead on some other ways to describe them. These involve issues whose importance went largely unrecognised until fairly recently. Three key issues for our purposes are that the reasoning follows a sequence of steps, that the reasoning is stated explicitly in words and/or symbols, and that the reasoning uses a crisp set categorisation where Socrates either is a man or isn’t, with no in-between values allowed.
So, why are these points important?
For some tasks, the sequence in which you perform the steps doesn’t matter. If we add 4 and 2 and 100, we’ll get the same result regardless of the order in which we add them together. For other tasks, however, sequencing is crucially important. For instance, if we multiply 4 by 2 and then add 100 to the result, we get a value of 108; if we instead add 2 to 100 and then multiply the result by 4, we get a value of 408.
Keeping track of the steps in sequences like these in your head is difficult, even for small problems like the ones above. It’s no accident that mathematics and formal logic are big on writing everything down, so that you’re not dependent on memory. Human working memory only has a capacity of a handful of items (about 7 plus or minus two). The multiplication example above requires remembering three initial numbers, two steps, another number (when you multiply two of the initial numbers together) and yet another number (when you add two of the numbers together). That takes you to seven items for a trivially small example. This is one reason that a lot of people hate maths and logic; they find those subjects difficult because of the limitations of the human cognitive system, but often blame the difficulty on themselves or on the subject area, rather than a simple cognitive limitation inherent in the human brain.
That leads us to the second point, about the reasoning being stated explicitly in words and/or symbols.
Spelling out the steps and the numbers explicitly in written words and symbols is an obvious way of getting past this bottleneck in human cognition, though it comes with the price of having to learn the writing system and specialist notations; another reason that a lot of people find maths and logic unwelcoming.
The combination of serial processing, reasoning stated in words/symbols, and writing is powerful, and lets you do things that wouldn’t be possible otherwise. These are very real advantages, and they can be applied to important problems in the real world, in long-established fields such as architecture, engineering and planning, which require calculations that most humans can’t do in their heads. It’s no surprise that this combination acquired high status very early in human civilisation, and still has high status in academia and in the rest of the world.
The third point, about crisp set categorisation, doesn’t necessarily have to be part of a package with serial processing and explicit reasoning, but has ended up frequently associated with them for largely historical reasons. Crisp sets involve sets (broadly equivalent to categories or groups) that have sharp boundaries; something either goes completely inside a set, or it goes outside it, with no intermediate states allowed.
In the Socrates example above, for instance, man is implicitly treated as a crisp set; either someone is a man, or they aren’t; similarly with mortal. The limitations of this approach were recognised from the outset, with ancient Greek philosophers asking questions such as at what point someone went from the category of “beardless” to “bearded” if these were bring treated as two crisp sets; just how many hairs were involved, and why that number of hairs rather than one more or one fewer? Up till the nineteenth century, such questions were generally answered by the academic establishment with the classic Ring Lardner response of “’Shut up,’ he explained”.
Problems with the serial processing/explicit reasoning/crisp set package
Then some researchers started using new approaches to logic, which turned out to be internally consistent, and to give very different and very useful results. Non-Euclidean geometry is one example; although many people loathed it at the time of its invention (Lovecraft used it in his horror stories as an indicator of eldritch monstrosity beyond sane human comprehension) it turned out to correspond with reality in unexpected ways; for example, satellite navigation systems depend on it. Another example is Zadeh’s invention of fuzzy logic, which provides a useful numerical and scalar way of handling concepts such as “fairly human” which the previous either human or not human binary systems couldn’t cope with.
Initial responses from the establishment to such concepts were mainly hostile, but gradually academic logicians and mathematicians came to accept them, and realise that they were important additions to the academic tool kit, as well as being compatible with the serial processing package. This news still hasn’t made it through to many school syllabus boards, so it’s possible to go through a high school education without hearing about anything other than old-style formal logic. This has far-reaching implications. A lot of public policy decisions by politicians, and decisions in organisations and in everyday life, are based on old-style logic and crisp sets, which are very limited and limiting in ways that we’ll look at later.
That’s one set of problems with the serial processing/explicit reasoning/crisp set package. There’s another set of problems which are less obvious, but which have equally important implications. These weren’t spotted until computing researchers tried tackling a problem which everyone assumed would be simple, but which turned out to be far more difficult than anyone had imagined. That problem was computer vision.
Back in the 1960s and 1970s, computer research was making dramatic progress in numerous directions. One direction that hadn’t been explored involved connecting a computer to a digital camera so that a computer could see its surroundings. That in turn would allow robots to see their surroundings and to make appropriate decisions about how to proceed; for instance, to identify obstacles and to plot a route round them. The first attempt to tackle this problem, at one of the world’s best research centres, assumed that this could be sorted out within a summer project. Over half a century later, this problem has turned out to be one of the most difficult, still only partially solved, challenges in computing. To demonstrate why it’s still a major problem, we’ll use the example of identifying the animal in a picture such as the one below.

https://commons.wikimedia.org/wiki/File:Walking_tiger_female.jpg
The parallel processing/associative networks/pattern matching package
If you try to identify the animal in the image using old-style formal logic, you might start with something like the following approach.
IF the animal is largeAND the animal is a carnivoreAND the animal has stripesTHEN the animal may be a tigerThere are some obvious weaknesses in this approach, such as the fuzzy definitional issue of what constitutes large, which we’ve mentioned above. A less obvious weakness involves issues that are easy to overlook because they’re so familiar. In this example, there’s the question of how you can tell that something is an animal; there’s also the question of how you can tell that something has stripes. If you ask someone how you can tell that something has stripes, they’ll almost certainly struggle to put an answer into words, even though they’ll know what stripes are, and can recognise stripes easily.
Early logicians didn’t get into the specifics of how you can define concepts like stripes, possibly because they viewed them as details as too trivial to deserve their attention. Early computer scientists had to tackle those specifics head-on to solve the computer vision problem. It rapidly became clear that they were far from trivial.
Cutting a very long story very short, it is just about possible to define some concepts like stripes using the serial processing package. However, doing so with that approach would be impractically slow even on the most powerful currently available computers, and would perform very poorly in anything other than tightly restricted settings, such as viewing items on factory production lines.
A much more effective and practical way of handling this problem is to use the parallel processing package. That’s what we humans use every day for tasks such as finding the front door key. It’s very fast, and it’s good at handling imperfect and incomplete information with “best guess” solutions, and it’s good at handling new situations, even if it isn’t always right. It’s very different, though, from the serial processing package, and it’s hardly ever mentioned in schools or in texts about problem solving or best practice. So what is the parallel processing package, and what are its implications?
The pair of images below show the core concepts. They represent input from a first layer of circles (on the right in both images) feeding into a central set of circles (in the centre in both images) which lead to a decision (the single circle on the left in both images). The first layer of circles represents cells in the retina of the eye; the second layer of circles represents cells in the brain. It’s a very, very simplified version of what actually happens in the brain, where billions of cells are involved, but it shows the key concepts.
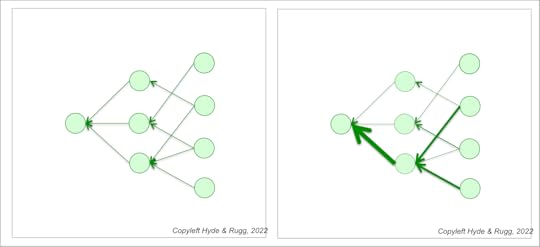
This is a network, and the cells within each layer work simultaneously with each other (in parallel). The retinal cells do their work first, and then pass their signals on to the brain cells for processing, so there’s an element of serial processing going on as well, but we’ll leave that to one side for the moment. In the very simplified diagram above, some of the retinal cells are connected to more than one brain cell; others aren’t. In the image on the left, all the connections are shown with the same strength of connection to each other; in the image on the right, some connections are much stronger than others, as shown by thicker lines.
What now happens is that the brain learns to associate a particular combination of actively firing cells in the network with a particular concept, such as tiger. This is an associative network, working via pattern matching (i.e. the pattern of cells being activated). In this example, one set of associations in the network tells you that the image shows an animal; another set tells you that it has four legs; another set tells you that it has stripes. Each of these sets will usually have different weightings, which the brain adjusts via experience. All these associations are working at the same time. There are no words involved until near the end; there’s just neurons firing. You can’t explicitly state what’s going on in the mental processing; all you could do is say which cells are active. This is very different from the serial processing package, where you can state explicitly what the steps of reasoning are, and what information is being used.
For our purposes, these are the key concepts, though the full version is somewhat more complicated…
In summary, then, the parallel processing package typically uses associative networks in the human brain, performing pattern matching, using parallel processing. It’s very different from the serial processing package, which uses explicit reasoning based on words and symbols, using serial processing.
Putting the pieces together
So, in brief, the human brain uses two very different approaches for reasoning. This isn’t a simple binary distinction like the pop psychology claims about left brained and right brained thinking. It’s more complex. Almost all non-trivial tasks involve a combination of both approaches, with rapid switching beween the two for different sub-tasks and sub-sub-tasks.
Many tasks inherently require a predominant use of one approach; for instance, solving a complicated equation draws heavily on the serial/explicit/crisp package, whereas identifying an object seen from an unfamiliar angle draws heavily on the parallel/associationist/pattern-matching package.
However, sometimes it’s possible to perform a particular task mainly via either one of these approaches. This can lead to communication problems if two people are using different approaches for the same problem. Here are some simple examples.
First example: If you’re counting something, such as how many screws came with an IKEA pack, you’ll probably do the counting as a serial process, but first you’ll have to use pattern matching and parallel processing to identify the screws, as opposed to other similar-sized components that may be in the same pack.
Second example: If you’re adding together numbers in a written list, you’ll probably use serial processing for the maths, but you’ll use pattern matching and parallel processing to identify what each of the numbers is in the list. If you’re doing a complex task of this type, you’ll do a lot of switching between the serial processing package and the parallel processing package.
Third example: I used the word probably in the previous paragraph because for counting small numbers, up to about seven plus or minus two, you can use either serial processing or parallel processing. For counting small numbers of items, you can “just tell” what the number is without counting them in sequence. This happens via a process known as subitising, which is parallel processing applied to counting. This is probably the mechanism used by animals that can count; interestingly, the upper limit that most animals can count to is about seven.
Fourth example: It’s possible to learn social skills by observing people, and learning the patterns in their behaviour nonverbally via parallel processing. Some people use this approach, and tend to be fluent in their social behaviour, even though they may have trouble describing the social rules in words. Other people have difficulty with this approach, and instead learn the rules explicitly, often via asking someone to explain them.
We’ll return to this topic in more depth and breadth in later articles.
Conclusion
In summary, there are two packages of mechanisms, processes and representations that are used by the human brain. These packages are very different from each other. One package is good for problems that require explicit, step-by-step reasoning that can’t be handled within human working memory. The other package is good for identifying what objects are, and for working with information that is incomplete, uncertain, or otherwise imperfect, to produce a “best guess” solution.
The two packages usually complement each other fairly neatly, with each being used for different types of problem. Sometimes, though, both packages can be applied to the same problem, and this can lead to trouble.
An example we used above involves learning social skills; if someone isn’t able to learn social skills via the parallel processing package, and instead had to learn via the serial processing package, then their social skills probably won’t be as fluent as they would have been otherwise.
Another example involves judgments in everyday life, such as assessing how safe an action would be, or assessing the claims of a political candidate. Using the parallel processing package in these contexts makes people susceptible to numerous biases and errors. The problem is made worse when the brain associates a particular concept with other concepts that have strong emotional values. A classic example of this is politicians giving “word salad” speeches, where the statements in the speech don’t make much or any sense from the viewpoint of the serial processing package, but are all strongly associated with positive values from the viewpoint of the parallel processing package. For someone making a snap decision, the parallel processing package gives a quick answer, which can be very useful in some situations, and very misleading in other situations.
Once you know about these packages, you’re in a much better position to work with them in ways that make the most of their separate strengths, and that reduce the risk of being let down by their separate weaknesses. For instance, you can learn how to spot patterns via the parallel processing package that will give you rapid insights that wouldn’t be possible via the serial processing package. A lot of professional training, in fields ranging from medical diagnosis to mechanical engineering, involves learning such patterns. Similarly, you can learn how to use the serial processing package to tackle systematically problems that are difficult or impossible to handle via the parallel processing package; that’s a key part of most formal training.
That’s a brief overview; we’ll return to these issues in more depth, and with examples from more fields, in later articles.
Notes and links
You’re welcome to use Hyde & Rugg copyleft images for any non-commercial purpose, including lectures, provided that you state that they’re copyleft Hyde & Rugg.
You might also find our websites useful:
This one is the larger version: https://www.hydeandrugg.com/
This one is intended for beginners: https://hydeandrugg.org/
April 5, 2022
Tacit knowledge: Can’t and won’t
By Gordon Rugg and Sue Gerrard
This is the third post in a short series on semi-tacit and tacit knowledge. The first article gave an overview of the topic, structured round a framework of what people do, don’t, can’t or won’t tell you. The second focused on the various types of do (explicit) and don’t (semi-tacit) knowledge. Here, we look at can’t (strictly tacit) and won’t knowledge.
The issues involved are summed up in the diagram below.

Can’t: Strictly tacit knowledge
The common factor in don’t knowledge is that the person involved can access the knowledge in some contexts, but not in all contexts. The common factor in can’t knowledge is that the person involved can’t immediately – if at all – access that knowledge explicitly in any context. They may be able to use the knowledge, and often use it at a very high level of skill, but they won’t be able to tell you what the knowledge is. They may refer to it using terms such as gut feel or intuition or muscle memory.
There are several types of can’t knowledge, each with very different implications. A common factor across these types is that the brain handles most tasks via massively parallel associative networks, rather than via step-by-step serial reasoning of the type used in classical formal logic. The parallel associative approach is much faster than the serial approach, but its contents and mechanisms are typically a “black box” inaccessible even to the person using it.
Compiled skills are skills that the person learned via explicit do knowledge, but they can now use without thinking, and would have to think hard to describe verbally. A classic example is changing gear when driving a vehicle; this skill starts as explicit do knowledge, but is increasingly handled by compiled can’t knowledge as the driver becomes more expert. Compiled skills are typically faster and more fluent than explicit do skills, as in the case of expert drivers. As a rule of thumb, if a person can carry out a task while maintaining a conversation, without a significant dip in performance, then they are probably using compiled skills.
Compiled skills typically require repeated practice over time, in the order of weeks or longer. They probably involve myelination of the neural pathways used in the task, making those pathways swifter and less susceptible to disruption. The nature of these pathways means that compiled skills are liable to strong but wrong errors, e.g. following your usual route to work and forgetting to detour to pick up a prescription from the pharmacy. Compiled skills often involve physical actions, which are sometimes referred to as muscle memory, but may also include sequences of mental actions.
Implicit learning involves someone gradually learning an association without being able to articulate that knowledge. This may take various forms. An early example in the research literature involved people in the poultry industry learning to tell whether a newly hatched chick is male or female without using surgical inspection. They were unable to explain how they knew whether the chick was male or female, but their judgments were correct almost all the time. Another example involved people predicting outputs from a simulated factory, again performing well, but without being able to articulate how their knowledge worked.
Implicit learning typically requires very large numbers of training examples, in the order of thousands or tens of thousands, and a significant training time, in the order of days or weeks.
Incidental learning is different from the processes above in that it can occur after a single example. It is also different in that it can occur explicitly, semi-tacitly, or tacitly. It involves learning something unintentionally while paying attention to something else.
For instance, a novice may see an expert perform a task in a particular way, and then perform the task in the same way as the expert. Sometimes this will happen explicitly, often accompanied by an “aha” moment; sometimes it will happen completely tacitly, with the beginner utterly unaware of where they learned to do the task in that way. The traditional apprentice task of sweeping the workplace floor provides extended opportunities for incidental learning.
Pattern matching is facilitated by associative networks; it’s the mechanism that most humans use to recognise familiar faces, or to tell that something is a pencil as opposed to a pen. It may occur at the level of surface features, or at the level of deep structure. For example, recognising a particular face involves surface feature pattern matching, whereas recognising that two different problems have the same underlying cause involves deep structure pattern matching.
Pattern matching is massively parallel, involving the cognitive processing of large numbers of items simultaneously. Face recognition, for instance, involves processing information about the component facial features as well as overall shape. This is very different from serial processing, which entails processing information one step at a time.
Parallel processing is much faster than serial processing, and can handle problems such as three dimensional pattern recognition that serial processing finds difficult or impossible. However, it is prone to errors that are the mirror image of its strengths, typically involving premature closure as soon as it finds a possible pattern match. This first match may be completely spurious, as in pareidolia. We’ll expand on parallel and sequential processing in the next post.
Won’t:
There are various reasons for people being unwilling to divulge information or knowledge, ranging from professional confidentiality to taboo topics and to criminal liability.
Projective methods can get at some won’t knowledge. These involve asking the person what someone else would do; for instance, What would a bad student do in this situation? This approach can be used with most elicitation methods; for example, you can ask someone to perform a card sort as if they were a dishonest customer.
Projective methods are useful for generating insights into what might be going on, but they need to be used with caution. One risk is that they will elicit stereotypes rather than responses based on direct factual experience. For instance, a response suggesting that members of a particular group will cheat in a test may well be a stereotype; however, a response saying that a bad student would cheat in a specific way might well indicate a mechanism for cheating that the examiners were previously unaware of.
Indirect observation involves observing proxies for a behaviour, as opposed to observing a behaviour itself. For instance, sociologists have used the dates of recorded marriages and first births as a way of indirectly observing the incidence of premarital sex in past times.
Conclusions and further thoughts
In this post, we’ve focused on the implications of can’t (i.e. strictly tacit) and won’t knowledge for eliciting people’s knowledge. There are also significant implications for other areas, such as:
How best to represent the different types of can’t and won’t knowledge (e.g. verbally, or schematically, or via images, or via senses other than visual)The interaction between these knowledge types and types of human error; for instance, compiled skills are particularly liable to causing strong but wrong errorsMapping these knowledge types onto techniques for teaching and learning; for instance, compiled skills will typically require at least two weeks of practice to become properly compiled, whereas incidental learning may occur within seconds.We will address these issues in later posts. We hope you have found this one interesting and useful.
Links and references
Card sorts: A short tutorial, and an in-depth tutorial.
Laddering: A short tutorial, and a longer tutorial (PDF download).
Observation:
An overviewThe STROBE method for making inferences about a working environment from observation.Identifying issues with the built environment, part 1Identifying issues with the built environment, part 2Reports: An overview that includes think-aloud, critical incident technique, hard case technique, and scenarios.
Content analysis:
A simple approachAn overview of content analysis methodsVisual representation of textsAssociative networks:
A brief overviewImplications for educationTypes of pattern matchingRequirements:
A series about the design processA series about about architecture and designUser Centred DesignAesthetics and design:
An overviewA more detailed discussion lBeyond the Golden mean: other regularities in aestheticsReference to original article:
The Maiden & Rugg ACRE reference is: Maiden, N.A.M. & Rugg, G. (1996). ACRE: a framework for acquisition of requirements. Software Engineering Journal, 11(3) pp. 183-192.
Copyleft: you’re welcome to use the image in this article for any non-commercial purpose, including lectures, as long as you retain the coplyleft statement within the image.
April 3, 2022
Explicit and semi-tacit knowledge
By Gordon Rugg and Sue Gerrard
This is the second in a series of posts about explicit, semi-tacit and tacit knowledge.
It’s structured around a four way model of whether people do, don’t, can’t or won’t state the knowledge. If they do state it, it is explicit knowledge, and can be accessed via any method. If people don’t, can’t or won’t state the knowledge, then it is some form of semi-tacit or strictly tacit knowledge, which can only be accessed via a limited set of methods such as observation, laddering or think-aloud.
This is summed up in the image below.
The previous article in this series gave an overview. In the present article, we focus on do and don’t knowledge, i.e. explicit and semi-tacit knowledge.
Do knowledge
This category includes various types of memory, communication and reasoning identified in psychology and related fields; for instance semantic memory (memory for facts, such as Paris is the capital of France) and episodic memory (memory for events, such as The time we went to Paris). These types of knowledge can be stated explicitly in words, and are amenable to being represented in classical formal logic and in software.
A first key point is that not all knowledge falls into the do category. A lot of knowledge cannot be stated explicitly in words, and cannot be easily represented in classical formal logic or in software. Handling these other types of knowledge can be done rigorously and systematically, but requires different approaches.
Don’t knowledge
This category includes various types of semi-tacit memory, communication and reasoning. A key feature of this category is that the knowledge involved is accessible, but is only accessible via a limited set of methods, such as think-aloud, observation, laddering, and card sorts, for reasons outlined below.
Short term memory: Knowledge in short term memory can be stated explicitly in words, but because its duration is very brief, an interview or questionnaire or focus group after the task would almost certainly fail to access it. The only realistic chance of accessing that knowledge would be to ask for it during the task; via think-aloud technique for instance.
Taken For Granted (TFG) knowledge is knowledge that the speaker/writer assumes to be so familiar to their audience that there is no need to mention it. This is one of Grice’s communication principles; it helps keep communications down to a manageable length. For instance, when you say something about your aunt, you don’t usually need to mention that she is female, because you can take it for granted that the person you’re talking to will know that this is part of the definition of “aunt”. However, if you’re talking about a second cousin once removed, you may need to say explicitly what that means, since not everyone knows the meaning of this term, so it can’t be taken for granted.
Taken For Granted knowledge is a common cause of misunderstandings and communication failures. These are often serious precisely because the concepts involved are likely to be fundamental ones; the fact that they are fundamental is what leads to people taking them for granted and not thinking that they need to be said explicitly. This situation often arises when experts in a field are interacting with non-experts, such as medical experts dealing with patients, or engineers in safety-critical fields dealing with members of the public. A typical example involves the expert telling the non-expert that if X happens, it will lead to Y, and taking it for granted that the non-expert knows how bad Y would be as an outcome.
Not Worth Mentioning (NWM) knowledge is similar to Taken For Granted knowledge, in that it involves knowledge being filtered out of a communication. The first key difference is that usually NWM knowledge is consciously, rather than unconsciously, filtered out. The second is that NWM knowledge is by definition considered by the speaker/writer to be trivial, whereas TFG knowledge is often considered by the speaker/writer to be extremely important.
NWM knowledge can cause problems when the speaker/writer is mistaken in their judgment that the knowledge is trivial. Often, something is trivial in one way but extremely important in another way. For instance, airborne dust may not be a problem from a respiratory health viewpoint in a workplace where all staff wear breathing gear, but may be a huge risk in terms of its potential for exploding, if the dust is from flammable materials.
Recognition and recall are known in different fields by various names, including passive memory and active memory respectively. Typically, people are better at recognising something when it is in front of them than they are at actively recalling something to memory. A classic example is asking someone to name states in the USA, or countries in the EU; people typically perform better at recognising the correct names from a list than at recalling them if asked to produce a list from memory.
Matching knowledge types onto elicitation methods
Each of the knowledge types above has significant implications for choice of appropriate elicitation method. These are summarised in the table below.
Type of semi-tacit knowledge Appropriate elicitation technique(s) Short term memoryThink-aloud, to catch someone’s thoughts in their own words before they’re lost from memory; Observation, to see what they doTaken For GrantedObservation, to see what they do; Laddering, to unpack their knowledge systematicallyNot Worth MentioningObservation, to see what they do; Laddering, to unpack their knowledge systematicallyRecognition and recallShowing examples, to jog their memory, combined with think-aloud to catch their short term memory responsesOther methods can also help when dealing with these types of knowledge. The table below gives examples; there’s a more detailed description here of different forms of report, including the methods in the table.
Method Useful for Remember Scenarios (“what would you do if…?”Rare or dangerous situations that can’t be studied directlyPeople’s predictions of their own future behaviour are often unreliableCritical incident technique/hard case techniqueTeasing out rare but important knowledgePeople’s memories of past events are often systematically distorted and unreliableReal-time commentary on someone elseAccessing short term memory knowledge about tasks where think-aloud isn’t possiblePeople’s judgments of the reasons for other people’s behaviour are often systematically distorted and unreliableThese methods can give valuable insights that might otherwise be missed, but the insights need to be treated with caution. There’s an extensive literature on biases in human judgment, memory, and beliefs about other people; a recurrent finding is that these biases are widespread, even among experts in the relevant field. An important related finding is that there’s little or no correlation between how vivid a memory or belief is, and how accurate that memory or belief is. This is why the table about knowledge types and elicitation techniques focuses on real-time techniques involving the person talking about their own performance, where the scope for biases and memory distortions is less.
It’s also possible to improve the chances of capturing TFG and NWM knowledge by using a representation that shows all the possible options, such as a table. When you populate the table with the knowledge you know about, you see at a glance where knowledge is missing.
Unfortunately, a lot of TFG and NWM knowledge involves isolated pieces of knowledge that don’t fit into a neatly tabular structure, such as “of course it’s more important to keep drivers alive than to protect the paintwork of the car”. Laddering uses a more flexible representation than a table, and offers a better chance of catching TFG and NWM knowledge by unpacking goals and explanations systematically, but laddering still doesn’t guarantee completeness. This is why we often advise using two or several appropriate methods in combination, to improve the chances of catching something with one method that the other missed.
Closing thoughts
The types of knowledge described above have serious implications for anyone trying to elicit valid knowledge from human beings. By their very nature, they require specific elicitation methods that correspond to the issues of memory, communication, etc that are involved; methods such as card sorts, laddering, think-aloud and observation.
In the next post we’ll look at can’t (i.e. strictly tacit) and won’t knowledge, their implications for choice of elicitation methods, and their implications for other areas such as human error, and education theory and practice.
Links and references
Card sorts: A short tutorial, and an in-depth tutorial.
Laddering: A short tutorial, and a longer tutorial (PDF download).
Observation:
An overviewThe STROBE method for making inferences about a working environment from observation.Identifying issues with the built environment, part 1Identifying issues with the built environment, part 2Reports: An overview that includes think-aloud, critical incident technique, hard case technique, and scenarios.
Content analysis:
A simple approachAn overview of content analysis methodsVisual representation of textsAssociative networks:
A brief overviewImplications for educationTypes of pattern matchingRequirements:
A series about the design processA series about about architecture and designUser Centred DesignAesthetics and design:
An overviewA more detailed discussion lBeyond the Golden mean: other regularities in aestheticsReference to original article:
The Maiden & Rugg ACRE reference is: Maiden, N.A.M. & Rugg, G. (1996). ACRE: a framework for acquisition of requirements. Software Engineering Journal, 11(3) pp. 183-192
March 29, 2022
Tacit and semi tacit knowledge: Overview
By Gordon Rugg and Sue Gerrard
Tacit knowledge is knowledge which, for whatever reason, is not explicitly stated. The concept of tacit knowledge is widely used, and has been applied to several very different types of knowledge, leading to potential confusion.
In this article, we describe various forms of knowledge that may be described as tacit in the broadest sense; we then discuss the underlying mechanisms involved, and the implications for handling knowledge. The approach we use derives from Gordon’s work with Neil Maiden on software requirements (Maiden & Rugg, 1996; reference at the end of this article).
In brief, the core issue can be summed up as whether people do, don’t, can’t or won’t state the knowledge. If they do state it, it is explicit knowledge, and can be accessed via any method. If people don’t, can’t or won’t state the knowledge, then it is some form of semi-tacit or strictly tacit knowledge, which can only be accessed via a limited set of methods such as observation, laddering or think-aloud. Because of the neurophysiological issues involved, interviews, questionnaires and focus groups are usually unable to access semi-tacit and tacit knowledge.
The image below shows the key issues in a nutshell; the rest of this article unpacks the issues and their implications. There are links at the end of the article to other articles on the methods mentioned in the table. The image below is copyleft; you’re welcome to use it for any non-commercial purpose, including lectures, as long as you retain the coplyleft statement as part of the image.

Knowledge that people do state explicitly is relatively straightforward to handle, though it still needs to be treated with caution because of the range of well-documented biases and shortcomings of human memory.
Knowledge that people don’t state explicitly may take several forms, caused by different mechanisms. A key point about this category is that people are perfectly willing and able to state the knowledge explicitly if asked about it. However, they are unlikely to mention this knowledge in interviews, questionnaires, or focus groups, for reasons described in more detail below.
Knowledge that people can’t state explicitly may also take several forms, caused by different mechanisms from those involved in don’t knowledge. A key point is that people are unable to access can’t knowledge, even if they are willing, and even if their lives literally depend on it, as in the case of gathering requirements for safety-critical systems.
Knowledge that people won’t state typically involves knowledge that the person involved is able to articulate; the key feature is the person’s unwillingness to articulate it. This unwillingness may be due to various reasons, including professional confidentiality, or the topic being taboo, or to conceal unethical or illegal activity. This knowledge can be accessed to some extent indirectly, via indirect observation or via projective methods.
Each of these four categories has different implications with regard to eliciting and handling the knowledge involved. Interviews, questionnaires and focus groups are able to handle do knowledge, but have only intermittent success with don’t knowledge, and are unable to handle can’t knowledge or won’t knowledge.
In the next articles in this series, we will look in more detail at the mechanisms involved in each of these four categories, and at the implications.
Conclusions and further thoughts
In this series of articles, we focus on the implications of semi-tacit and strictly tacit knowledge for eliciting knowledge from people. There are also significant implications for other areas, such as:
How best to represent the different types of semi-tacit and strictly tacit knowledge (e.g. verbally, or schematically, or via images, or via senses other than visual)The interaction between these knowledge types and types of human error; for instance, compiled skills are particularly liable to causing strong but wrong errorsMapping these knowledge types onto techniques for teaching and learning; for instance, compiled skills will typically require at least two weeks of practice to become properly compiled, whereas incidental learning may occur within seconds.We have addressed some of these issues in previous articles. For instance, this article looks at the mapping between types of measurement and appropriate choice of visualisation, and this article looks at how the knowledge types above map onto teaching and learning methods.
We will address these issues again in later articles. We hope you have found this article interesting and useful.
Links and references
If you’d like to learn more about the methods described above, you may find the links below useful as a starting point.
For card sorts, this in-depth tutorial includes references to useful papers in the academic literature. There is a shorter tutorial here.
This article is a short tutorial on laddering. There is a longer tutorial here (PDF download).
This overview describes different types of observation. The STROBE method is useful for making inferences about a working environment from observation. This article and this article describe ways of observing people’s experiences with the built environment (e.g. bad doorway design).
This summary covers various types of report, including think-aloud, critical incident technique, hard case technique, and scenarios.
For content analysis, we describe a simple approach and other verbal/numeric approaches, including transcripts of people’s interviews and think-alouds. This visual representation lets you identify structures in a text; we use an example showing what you can tell from hesitation noises.
In this article we give a brief account of how the brain uses associationist networks to do parallel processing, and discusses some of the practical implications. Here, we look at some of the implications for education theory and practice, and here we look in more depth at different forms of pattern matching, and their implications.
There are numerous articles on this blog about gathering requirements systematically, and about integrating the approach described here with systematic design. Topics include this short series about requirements; User Centred Design, and this short series about architecture and design. There are a lot of others; searching within the blog for “requirements” and “design” will find them.
We’ve also blogged repeatedly about aesthetics, a topic which overlaps significantly with tacit knowledge. This article gives an overview; this one looks in more depth at some of the issues involved; again, a search within the blog is a good place to start.
The categorisation we use here is derived from a 1996 journal article by by Neil Maiden and Gordon Rugg. That article unpacks the concepts involved in detail, using a faceted taxonomy. The version described here is a simpler version of that taxonomy, intended for everyday use.
The Maiden & Rugg ACRE reference is: Maiden, N.A.M. & Rugg, G. (1996). ACRE: a framework for acquisition of requirements. Software Engineering Journal, 11(3) pp. 183-192
September 7, 2021
The gulf of instantiation
By Gordon Rugg
Two of the most common complaints about managers and about teachers/lecturers are:
They’re too vagueThey’re too specificAlthough these complaints are opposites, the underlying problem for both of them is the same. It involves the gulf of instantiation, which is the topic of this article.

The diagram above shows the key concept. Each of the black circles represents a tangible action, tangible item, or tangible event. The key point is the tangibility; you can point to the action or item or event. You’re dealing with reality, not with opinions or abstractions. This level of reality is technically known in knowledge representation as the instance level.
The counterpart to the instance level is the abstraction level. In the diagram above, the green circles represent two levels of abstraction. The dark green circles are at a lower level; the lighter green circle is above them, on a higher level.
The abstractions may take various forms, such as classification systems, or layers of explanation, or layers of sub-tasks. For example, in a classification system the dark green circles may represent the categories of cat, rabbit and dog, and the light green circle may represent the higher-level category of animals, with the black circles being individual cats, rabbits and dogs.
Abstraction levels are by definition abstract; you can’t point at something and say it’s the class of “igneous rocks” or “major land battles” or whatever. You can point at an individual rock and say that it belongs to a particular class, but when you do this, you’re pointing at something on the instance level, among the black circles, not at the class level.
So how does this map onto education and management? It maps on like this.
Education and management
Individual items at the instance level only have very limited power. Knowing a single fact, or how to do a single action, doesn’t usually get you very far. For example, knowing how to do a single action on an assembly line, such as welding a particular connection, won’t help you if you need to weld something different, such as a different metal, or a different thickness of components. Teaching and giving instructions only at this level is usually too specific.
This is where craft skills come in. Craft skills involve joining up this sort of knowledge, working upwards from the instance level into more general principles, as in the diagram below. The diagram shows how the instance-level items have been collected into three groups. This might, for instance, represent one group of knowledge about welding, another group about soldering, and a third group about riveting.
This sort of knowledge is valuable, but is often not appreciated enough. One reason is that it usually involves low-status manual work. Another is that it is limited in its power. In the diagram below, the three classes aren’t joined to each other at a higher level. The light green circle, representing higher-level knowledge, isn’t connected to the lower-level dark green circles.

This is where “just the facts” approaches and training courses can lead to learners becoming frustrated, because they’re being taught the “what” without any “why” to make sense of it. The higher-level linkages provide the “why”.
Approaches that focus only on the higher levels can be frustrating because they don’t specify how to go from the abstraction level (e.g. “activate the flux capacitor”) to the instance level (e.g. “press this button, then that button”). This leads to complaints about being too vague or too abstract.
In an ideal world, education and training would provide a completely joined up set of knowledge, with no gaps between abstract principles and tangible instances where they cross the gulf of instantiation, as in the diagram below.

In practice, however, the amount of knowledge involved is usually so vast that joining it all together is not possible. Research into expertise has consistently found that even within a narrowly defined area of expertise, the number of pieces of information required for that expertise is in the tens or hundreds of thousands. So, choices have to be made about how to cross that gulf of instantiation, and about where to cross it.
The diagram below shows how these choices map onto an old divide in the education world between universities and polytechnics. In this idealised model, universities focus on the higher levels of abstraction, which give more understanding of the key general principles, at the expense of the instance level. Polytechnics, in this model, focus on the instance level and the lower levels of abstraction, giving more directly applicable knowledge, at the expense of understanding broader unifying principles.

In practice, as you might expect, things aren’t quite this clear-cut. University courses normally include practical classes where students learn how to cross the gulf of instantiation between abstract concepts from the lectures, and tangible actions and objects at the instance level in the real world; for example, how to translate abstract database theory into how to use this instance of a database. Case studies are another well established way of crossing the gulf of instantiation.
These two approaches help with the gulf of instantiation, but in practice they only provide partial coverage. There’s a tendency for universities to assume that the students can work out for themselves how to cross the gulf of instantiation for anything not covered in practicals or case studies. In reality, this assumption is optimistic. Typically, there’s variation in how completely the gulf is crossed within a course or module, ranging from no instantiation for some topics, through partial instantiation for others, to complete instantiation for yet others, as shown below.

From the polytechnic perspective, a lot of research breakthroughs came from problems at the level of craft skills and instantiation, often when industry couldn’t get any further by trial and error, and couldn’t see how to get further forward.
The concepts above map neatly onto management. Some classic forms of bad management are:
Giving orders only at the instance level. This is usually perceived as micromanagement, which is very unpopular. It also means that if something unexpected happens, the person involved has no idea of the broader context and of how to respond appropriately.
Giving abstract orders which can’t be fully instantiated. Sometimes the orders can’t be instantiated because the person involved doesn’t know how. Sometimes, the orders can’t be instantiated because they’re physically impossible.
So, crossing the gulf of instantiation is an inherently hard problem. However, the concept of the gulf of instantiation is a useful conceptual tool that makes it easier to work out ways of crossing the gulf, rather than just complaining about people being too vague or being too specific. Which raises the question of just how to cross the gulf more efficiently…
Crossing the gulf
The gulf of instantiation is a significant problem in computing, though it’s usually referred to by other terms, such as instantiation. There are numerous types of formalised diagrams, such as flowcharts and ERDs, whose purpose is to force designers to instantiate just what happens where and how. None of these formalisms is perfect for all purposes; even within a single purpose, any given formalism still has its limitations, so there has been a continuous churn in terms of which formalisms are popular at a given time. Still, despite being imperfect, they’re a lot better than nothing.
In brief, any systematic representation will help reduce problems with the gulf of instantiation. Systematic representations are particularly likely to help with semi-tacit knowledge such as Taken For Granted (TFG) and Not Worth Mentioning (NWM) points; by definition, these are not normally mentioned explicitly, and are a rich source of miscommunication problems. The “wh” questions in English are a simple example of how to instantiate, by reminding the user to think about who, what, where, when, why, and how.
Although bridging the gulf completely isn’t feasible for something as large as a taught degree course, it becomes a lot more feasible when dealing with smaller problems. Bridging the gap reduces the likelihood of failure, which is important for safety-critical systems in which failure may be catastrophic. It’s also important in everyday systems for reducing failure demand (i.e. having to fix problems caused by not doing something right the first time round).
There’s a lot about representations elsewhere on this blog. They’re typically cheap, quick, and simple to use once you learn them, but they’re not as widely used as they should be. They’re well worth exploring.
Research, theory and the world
If you’re into theory of knowledge and the scientific method, you can apply the gulf of instantiation to research and ideology as well as to teaching and management. There’s a long tradition of people generating hugely elaborate abstract models, and either ignoring the gulf of instantiation completely or only mentioning the points where their model does manage to cross the gulf, while ignoring the points where it fails dismally to cross the gulf. As usual, Plato has a lot to answer for on this score, but there are also plenty of more modern individuals to share the blame.
There’s widespread agreement that good theories are elegant and powerful, but there’s widespread disagreement about how to define elegance and power. One way of defining them is via graph theory, using the concepts of the instance level and levels of abstraction to measure descriptive power, predictive power, and elegance.
We can define the descriptive power of a theory in terms of how many instances that theory links to. For example, a theory which says that an invisible black cat created the observable universe has very high descriptive power, because it links to every instance that exists. It’s a powerful theory in terms of descriptive power, but it has obvious limitations.
The predictive power of a theory can be very different from the descriptive power. Predictive power is about predicting where new instances will be found; the more new places, the more powerful the theory. The invisible black cat theory fails badly in terms of predictive power. A classic example of a theory with high predictive power is the periodic table, which not only correctly predicted the existence of elements not yet discovered, but also correctly predicted the properties of those elements. You can further refine this by looking at the proportion of correct predictions to wrong predictions, to weed out predictions so broad that they’re useless in practice.
The elegance of a theory can be defined in terms of how many links it contains at the abstraction levels; the fewer the links, the more elegant the theory. Typically, scientific theories aim to be highly elegant, with high predictive power and high descriptive power.
Much could be said about how these concepts map onto philosophy, theology and conspiracy theories, and much doubtless will be said, but that’s another topic…
Notes and links
You’re welcome to use Hyde & Rugg copyleft images for any non-commercial purpose, including lectures, provided that you state that they’re copyleft Hyde & Rugg.
You might also find our websites useful:
This one is the larger version: https://www.hydeandrugg.com/
This one is intended for beginners: https://hydeandrugg.org/
abstraction, educationneat ideas from unusual places
abstraction, educationabstraction, educationDecember 9, 2020
What’s so great about live lectures anyway?
By Gordon Rugg
So what’s so great about live lectures anyway, and why do people get so worked up about whether to put lectures online?
Live lectures have some significant advantages over other media; however, these advantages can be difficult to put into words unless you’ve encountered the relevant bodies of research and practice. This can be very frustrating if your employer wants to put everything online for whatever reason, and if they think that anyone who disagrees is simply a lazy Luddite unwilling and unable to change with the times.
There are very real reasons for including face to face lectures, tutorials etc in education and training. However, some important reasons aren’t as widely known as they should be. In this article, I’ll look at these reasons, and then consider the implications for choice of delivery methods in education.
The first reason I’ll look at involves reading the audience’s reactions so you can modify the delivery in real time. Some lecturers take this for granted; others appear never to have thought of it.
The second involves hard information and soft information, and how these interact with issues such as front versions and back versions.
I’ll also look briefly at the knowledge pyramid, which consists of data, information and knowledge.
Finally, I’ll consider some historical context, before pulling together some recommendations for choice of delivery methods.
Reading the audience, and types of people
At their best, live lectures can be life-changing. At their worst, they use up a chunk of your life that you’ll never have again. The tricky bit is that what one student thinks is a life-changing event, another student may hate. So what’s going on there?
One major factor is that when you’re giving a live lecture, you can read the audience, and you can adapt the lecture in real time in response to the audience’s nonverbal feedback. For example, if they’re looking bored, you move swiftly on; if they’re looking puzzled, you slow down and go into more detail.
A related advantage of live lectures is that you can spin off onto a different topic that suddenly and unexpectedly turns out to need coverage. For example, you mention a technical term that you think the students already know, but they look blank, and you realised that you need to explain it. For some key concepts, this is not going to be a one-sentence explanation; instead, it will take several minutes. In a live lecture, you can do this.
There are other reasons, and I’ll return to them later, but for the moment I’ll focus on the two above.
It was a surprise to me when I realised that not all lecturers take this for granted. It was also a surprise when I realised that not all students like this approach. So what’s going on?
What I think is going on is as follows. Some people prefer to have information presented in a format that they’re expecting, with the minimum of departure from that format, and with the minimum of distraction. Others prefer to have information presented in a richer, less predictable format, with more memory cues via throwaway anecdotes, and with immediate clarification of points that they don’t understand.
Phrased this way, both viewpoints make sense. However, this means that some students will hate the same features of live lectures that other students love. We can show this in a table, similar to the one in another article about mismatches between expressive and instrumental behaviour, in the context of doctors interacting with patients.
The table below shows the mapping between the two viewpoints on lectures, and the type of student feedback which each combination is likely to produce.

This model has significant implications for how we handle student feedback. It implies that there are two populations of student, whose ideas about what constitutes a “good lecture” are mutually incompatible. This is why a lecture that gets brilliant overall feedback from one group of students can get dreadful overall feedback from another group of students. The feedback reflects the proportion of students who happen to match the style of the lecture, rather than reflecting the lecture in itself.
This has far-reaching implications for assessment of lecturers’ job performance, where there is often an implicit assumption that negative feedback from students reflects failings on the part of the lecturer that can and should be remedied. That, however, is another topic, for another article.
Types of knowledge: Front versus back, and hard versus soft
Returning to the theme of live lectures versus other methods of delivery, another major advantage of live lectures is that you can use them to tell students about things that they need to know, but that you have no intention of putting in writing with your name on it. These often involve the dirty underbelly of how things actually happen in the workplace. There’s an entire genre of instructive stories that begin: “Back in the day, when this was legal, a lot of employers…”
These concepts are well known and well codified in some disciplines, but not in others. The concepts of front versions and back versions were described in depth by Goffman in 1959, in his book The Presentation of Self in Everyday Life, and are taken for granted in sociology and related disciplines. The related concepts of hard information and soft information have likewise been in widespread use for decades in information systems research and practice, where they’re an important part of Checkland’s Soft Systems Methodology (SSM). In many disciplines, however, these concepts are little known.
In brief, the front version is the version that a group shows to outsiders, and the back version is the version used by group members. Sometimes this involves dishonesty, but usually it involves agreed norms, and what are considered to be appropriate forms of behaviour. An example is airline pilots presenting a front version to passengers of being calm and in control, even if the back version involves worries about catastrophic engine failure.
Hard information and soft information relate closely to these concepts, but are not the same. Hard information is information stored on some long-term medium, such as written text on paper; soft information is ephemeral, such as a conversation in the corridor. Historically, this was a fairly crisp distinction, with significant implications. Some types of information handling, such as customer records, are better suited to treatment as hard information. Others, such as giving real-time updates to colleagues about fast-changing situations, are better suited to soft information. A key part of joining a discipline is learning about back versions and group norms. Similarly, learning when to use hard information and when to use soft information is an important part of learning how to do a job.
Historically, there was a fairly close mapping between front versions and hard information, and between back versions and soft information. There was an interesting liminal area where the decision might be made to treat something via hard information and front versions as a precaution, doing something “by the book” and “with a paper trail” if there was a perceived risk of future problems.
In the past, this meant that lecturers could present front versions via hard information, in forms such as lecture slides for students, and could present back versions via soft information such as lectures and tutorials.
This situation changed with the spread of technologies such as mobile phones, which could record a live lecture and transform it from soft information into hard information, with all the associated implications of lecturers’ words potentially coming back to cause them problems later.
In some fields, this is not a significant risk; if you’re telling students about the properties of plagioclase feldspar, you’re unlikely to provoke international controversy on Twitter. In other fields, this is a huge risk, if you’re trying to make students aware of sensitive issues in their chosen discipline where they could easily blunder into massively politicised issues without being aware of what they had done.
This can produce a significant chilling effect, where there’s a strong temptation for lecturers just to cover the uncontroversial topics and the front versions.
So, in summary for the points so far:
Live lectures allow the lecturer to modify the lecture in real time, in response to the audience’s reactions. Some lecturers and some students consider this a good thing; others consider it a bad thing.
Historically, live lectures provided a soft information route for lecturers to tell students about back versions that they needed to know about. This route is becoming more difficult because of recording devices that can turn any lecture into hard information, with an accompanying chilling effect.
Those are two issues about live lectures that are well recognised in some fields but not in others. There are other issues, some of which I’ve blogged about previously; in the next section, I’ll briefly discuss assorted other issues, then pull the results together into a summay of advantages and disadvantages of different delivery methods.
Types of knowledge: The knowledge pyramid
There’s a useful distinction in computing between data, information and knowledge. I’ve blogged about this topic here and here.
A simple definition of data in this context is just numbers, such as 814. These numbers are meaningless without a surrounding structure; for instance, 814 could be a house number, or the reading on a measuring device, or a historical date.
Information in this context is structured data; for example, the information that Charlemagne died in 814, where the number (data) is given meaning by the context of being a death date.
Knowledge is information about information. For example, Dark Age dates don’t map perfectly onto current calendar systems, because of the calendrical year in early European calendar systems not starting on January 1, and assorted other factors.
If we map this distinction onto the choice between live lectures and other forms of delivery, then it makes sense to use live lectures primarily for knowledge, where the concepts are more complex, and more liable to misunderstandings. Live lectures make it easier for the lecturer to judge whether the students have grasped an explanation that involves knowledge, or whether they need more explanation from a different angle. Data and information can be handled via hard information media, such as textbooks and online resources.
Types of communication: Synchronous versus asynchronous
This distinction is widely known, so I’ll keep this section brief.
Synchronous communication is real-time; asynchronous communication isn’t. A conversation by phone or video conference is synchronous; an email exchange, which is asynchronous, has a delay between one person’s communication going out, and another person’s receiving it.
Synchronous communication is faster than asynchronous. In a synchronous live lecture, if a student has a question, they can ask it immediately and get a response immediately. With an asynchronous recorded lecture stored online, if the student has a question, the speed of response can range from a few seconds (e.g. if the lecturer is available for online messaging at the time when the student views the lecture) to hours or days (e.g. if the student has to email the question to a lecturer during their office hours).
However, speed of response can come at a price; an immediate response may not be as accurate or well formulated as a thought-through, asynchronous response.
Historical factors
A complicating factor in discussion of live lectures is the historical and sociotechnical background. Historically, lectures provided a cheap way of disseminating knowledge, information and data, when books and related materials were expensive. This meant that by the time of cheap printed materials, the lecture was well established as the main default method of educational delivery.
This issue overlaps considerably with social factors, particularly power and status. The physical layout of the lecture theatre also imposes many sociotechnical constraints; we’ve blogged about this here.
Pulling it together: Which medium for which content?
Live lectures are good for real-time modification of the lecture in response to the audience’s reactions. Lectures are also good for covering soft information and back versions if they aren’t recorded. They’re variable as regards quality of responses to questions; they work well for questions with simple answers, but are more problematic for questions with complex answers.
In summary: Live lectures make it possible to deliver types of knowledge and feedback that aren’t feasible for recorded lectures. The converse is also true. These and other delivery mechanisms, such as project-based learning, should be viewed as complementary parts of a whole, and should be used systematically in combination with each other.
Notes and links
You’re welcome to use Hyde & Rugg copyleft images for any non-commercial purpose, including lectures, provided that you state that they’re copyleft Hyde & Rugg.
There’s more about the theory behind this article in my book Blind Spot, by Gordon Rugg with Joseph D’Agnese.
You might also find our website useful.
July 2, 2020
Games people play, and their implications
By Gordon Rugg
There are regularities in how people behave. There are numerous ways of categorising these regularities, each with assorted advantages and disadvantages.
The approach to categorisation of these regularities that I’ll discuss in this article is Transactional Analysis (TA), developed by Eric Berne and his colleagues. TA is designed to be easily understood by ordinary people, and it prefers to use everyday terms for the regularities it describes.
I find TA fascinating and tantalising. On the plus side, it contains a lot of powerful insights into human behaviour; it contains a lot of clear, rigorous analysis; it has very practical implications. On the negative side, it doesn’t make use of a lot of well-established methods and concepts from other fields that would give it a lot more power. It’s never really taken off, although it has a strong popular following.
An illustrative example of why it’s fallen short of its potential is the name of Berne’s classic book on the topic, Games People Play. When you read the book, the explanation of the name makes perfect sense, and the deadly seriousness of games becomes very apparent. However, if you don’t read the book, and you only look at the title, then it’s easy to assume that the book and the approach it describes are about trivial passtimes, rather than core features of human behaviour.
In this article, I’ll look at some core concepts of Transactional Analysis, and how they give powerful insights into profoundly serious issues in entertainment, in politics, and in science.
The image below shows games at their most deadly serious; Roman gladiatorial combat, where losing could mean death.
By Unknown author – Livius.org, Public Domain, https://commons.wikimedia.org/w/index.php?curid=3479030
Some games that people play
I’ll focus on one part of Transactional Analysis, that deals with how people structure their interactions with each other and with life. It’s summed up neatly in the title of another book by Berne, namely What do you say after you say hello?
Here’s a simple-looking example of how this works.
You’re at the bus stop, alone, and another person arrives at the same bus stop. You’re in a part of the world where it it’s polite to acknowledge the other person’s presence, so you each say hello. Now what?
One option is to make a neutral comment that lets the other person engage in conversation if they wish. In the UK, a traditional safe neutral topic is when the bus is likely to arrive. So, you wonder out loud when the bus will arrive. Now the game gets going.
The other person can draw on a large number of well-established structures for their response. In TA, these have names from everyday life, like Ain’t it awful? and Happy to help.
If the other person wants to play Ain’t it awful they can respond to your neutral opening by saying something like “It will probably be late; they usually are these days”. This tells you the game that they want to play. You now have the option of joining them in that game, or of signalling that you want to play a different game.
So, within three sentences, you each know that the other is interested in interacting, and that the other person wants to complain about life. If you are happy to play the same game as them, you can now have a conversation on shared safe ground.
That’s the basic form. There are more complex forms, but the basic form is that simple. Berne and his colleagues identified about a hundred games; enough to give plenty of options for interactions, but a tractably small number from the viewpoint of analysis. Because TA is a deliberately informal approach, these games aren’t treated as cast in stone; TA practitioners and groups routinely adapt and create their own descriptions of games. Some game labels are widely shared across the TA community; others are less widely used.
In this article, I’ll look at three games in particular, namely General Motors, Ain’t it awful and Look, Ma, no hands. I’ll examine how these help make sense of the entertainment industry, of politics, and of science as social activity.
Games people play, and entertainment
The underlying structure of General Motors is that the players debate the relative merits of different entities from the same field. The example that gives this game its name is people back in the day debating the relative merits of car manufacturers; for example, one person arguing that General Motors is better than Ford, and another person arguing that Ford is better than General Motors, and so on for other manufacturers. A key feature of the game is that it isn’t about reaching an agreed decision or about having winners and losers; instead, it’s a structure for conversation that gives the participants a shared, agreed framework within which they can debate safely for as long as they want.
Once you know what General Motors looks like, you realise that it’s been around for a very long time, and that it’s ubiquitous.
One of the earliest recorded versions of General Motors involves Roman gladiators. Classic Roman gladiatorial combat was highly structured. Each fight involved two gladiators, and a referee. In the image at the start of this article, the referee is the man in the toga with a stick. The combat had rules, which were enforced by the referee. There were also established types of gladiator in classic gladiatorial games, such as the hoplomachus (a heavily armoured fighter) and the retiarius, armed with a net and a trident.
This is where General Motors comes in. The classic types of gladiator were routinely paired against each other in ways that complemented the strengths and weaknesses of each type. For example, the retiarius, who had light armour but a long trident, was usually paired against the secutor, who was heavily armoured, but had a short sword.
This made it very easy for Romans who were keen on gladiatorial combat to play General Motors. There was a tractable number of different types of gladiator, each with iconic, clearly defined, distinguishing features, who fought each other regularly, and gave spectators plenty of examples of what happened when a gladiator of one type fought against another type. The spectators could then argue forever about general principles and about specific matches.
Fast-forwarding to the present: Exactly the same game of General Motors is a central feature of some of the most successful entertainment franchises in the world. Pokemon has the same deep structure; the Marvel universe has the same deep structure. These franchises not only provide spectacle for their audience; they also have a structure that makes it easy for fans to interact with each other in a way that strengthens their allegiance to the franchise and to material relating to their favoured gladiator/pokemon/character.
This isn’t the only TA game that applies to the world of entertainment; there are plenty of others, such as Mine’s better than yours, which is the basis for the whole of competitive sport. It’s a fine, rich territory for exploration. For brevity, though, I won’t try to do an overview; this article is just a taster.
The example of gladiatorial combat makes it very clear that games are not always harmless fun; on the contrary, they can be literally a matter of life and death. Once you get your head round this point, then Berne’s use of the word “game” makes sense, but a different choice of word would probably have strengthened his case. Anyway, on to another deadly serious area where TA gives useful insights.
Games people play, and the dark side of entertainment
A key feature of games in the TA sense is that they’re expressive behaviour; they’re primarily about showing what sort of person you are. This is very different from instrumental behaviour, which is about getting something done. Sometimes, however, behaviour is both expressive and instrumental, often with far-reaching implications. These implications are often unexpected and unintended by the people involved, although those same implications may be very obvious indeed to other people.
First, a brief description of expressive and instrumental behaviour. A given behaviour can be described in terms of how strongly expressive it is, and how strongly instrumental it is. A sneeze is usually neither particularly expressive nor particularly instrumental; it’s a simple reflex action with no intended signals or consequences. Wearing a baseball cap with a political slogan is highly expressive in terms of the slogan, and may be moderately instrumental in terms of keeping the sun out of your eyes. A hard hat is usually highly instrumental, in terms of protecting your head from injury, and usually low on expressive behaviour. A Roman centurion’s helmet is both highly instrumental, in terms of protecting the wearer’s head, and highly expressive, in terms of signalling the wearer’s rank and status.
Returning to TA games: A key point about games like Ain’t it awful and General Motors is that they’re not intended to produce a practical answer to a problem. People playing those games typically react badly if you suggest a way of getting the buses to run on time, or of displaying the pros and cons of cars or gladiator types as a spreadsheet based on data. The games exist to provide an agreed structure for a conversation, where the parties involved enjoy the conversation. Finding a definitive answer would end the conversation, and spoil the fun.
Sometimes, though, TA games collide with practical, instrumental reality. It’s usually a case of “collide” rather than “happily intersect”.
An example from popular culture is the “ancient mysteries” genre in television. This genre enables viewers to play General Motors with their own favoured explanations for the alleged mystery. On the surface, this may look like a democratisation of research, and a chance for ordinary people to contribute new ideas. When you look deeper, however, something murkier is happening.
One key underpinning assumption of “ancient mystery” shows is that there actually is an unsolved mystery in the first place. This in turn usually means an assumption that mainstream experts have failed to find an answer. This in turn means that the show won’t give an accurate overview of the current specialist literature on the topic, since that would destroy the central premise of the show. It also means that since mainstream experts are portrayed as having failed, there is an implicit assumption that their opinions can be discounted, and that viewers’ opinions offer fresh insights that may well be correct.
This wouldn’t be a huge problem if it only affected a handful of alleged “ancient mysteries”. However, that isn’t the case; it’s occurring against a long tradition of resenting and denigrating expertise.
Games people play, and politics
The issue of not wanting to find a real answer can become a serious problem when TA games interact with politics, and when there are misunderstandings about whether someone intends a statement to be expressive or instrumental.
One potential area of interaction is agenda setting in politics, which involves politicians, political commentators and the media choosing the topics where they will focus their attention. TA games such as Ain’t it awful are about a topic; if that topic gets picked up and added to a political agenda, then it can suddenly change from a relatively harmless piece of expressive behaviour into real instrumental behaviour with real world consequences.
Moral panics are a classic example of this. An Ain’t it awful topic gets picked up by somone with a political agenda, and turned into something that can drastically change lives. There’s been a lot of good research into moral panics; their pattern is pretty much constant. They’ve been around since at least ancient Roman times, and probably long before.
A good example is the Satanic ritual abuse panic of the 1980s, which started off in the world of evangelical redemption stories. These stories typically take the form of: “I did all these very bad things, but then I was born again, and now I’m saved”. The worse the things, the better the redemption, and the greater the temptation simply to invent very bad past sins to gain more kudos for having a bigger redemption.
That’s relatively harmless when someone is making false claims to have done hard drugs or shoplifted. It’s a completely different game when someone claims to have been part of a Satanic cult that murdered babies. The police can’t simply ignore such claims, so when a book came out in 1980 making these claims, the topic soon became part of the mainstream political agenda.
After a few years, the impossibility of many of the claims, and the significant absence of evidence for others, gradually led to the panic subsiding. However, a lot of people had their lives ruined by false accusations along the way, including some who were imprisoned for decades.
Another potential area of interaction between TA games and politics is when politicians themselves are playing games, such as Look how hard I’m trying. This is more likely to be an issue with idealogues and amateur politicians than with professional politicians. For idealogues and amateur politicians, trying and failing to get a policy made into law can act as a strong signal to the base. As with moral panics, such topics can become a serious problem if they start getting treated seriously by people with power, often as part of a cynical strategy to gather more votes. Usually it becomes clear eventually why those policies had not been treated seriously before, but usually a lot of damage has been done by that point.
Games people play, and science
The examples above involve TA games from the dark side. Some TA games, however, are more healthy. I’ll look briefly at some examples that often occur in research and in education.
The first is Look Ma, no hands (as in riding a bicycle with no hands). There’s a long tradition in research of showing off intellectually by doing something that has never been done before, preferably with as little evidence of effort as possible. Euler, for example, invented graph theory in an afternoon, as a piece of mental exercise. It’s a major area of mathematics which is a core part of how the Internet works and of how satellite navigation systems work, among many other things. Look Ma, no hands can be irritating to those in the vicinity, but it’s a powerful motivator for new discoveries and inventions.
Two games that are usually straightforward ways of making the world a better place are Happy to help and Wise old sage. Both of them are what they sound like.
A lot of key insights in research come from colleagues who make time to help solve a problem, even if there’s nothing in it for them. Players of Happy to help span the academic world from Nobel prize winners to technical support staff. By a fascinating coincidence, they are usually more likely to offer help to people who are reasonably decent human beings, rather than to selfish unpleasant ratbags. Sometimes there is some justice in the world…
Education tends to attract players of Wise old sage, though you encounter them in most walks of life, to varying degree. This game is similar to Happy to help but is not the same.
Usually Happy to help is about specific, clearly identifiable problems or solutions relating to your work. A classic example in research is when you’re trying to make sense of something that looks horribly messy, and then a helpful colleague introduces you to a beautifully simple solution from another field that nobody had ever applied to that problem before. Often, all it takes is a single sentence, like “You could handle that with a faceted taxonomy”. You can then take that solution and run with it.
With Wise old sage the insights are usually less clear cut, and are often about you and how you view the world. There’s a whole genre of Zen-style advice from PhD supervisors to their long-suffering students that takes this form, such as: “Take the obvious and reverse it,” and “Sometimes the question is the answer”. Neither of these is actually from Zen canon; the first is from the film The Halls of Montezuma, and the second from a Barbara Hambly fantasy novel, but that’s a minor detail. The key point is that both of these insights can profoundly change the way that you think about the world. Happy to help is like giving someone a fish; very useful if they need a fish right now. Wise old sage is like teaching someone how to fish; very useful for anyone who needs to deal with fish in the long term.
Closing thoughts
That’s a brief taster of some Transactional Analysis games. They give very useful insights into why people behave in ways that appear irrational and inconsistent, and into the underlying regularities and motivations in those behaviours. Once you know those regularities and motivations, then you’re much more able to handle them. For example, if you’re dealing with customers or clients, then the way that you handle a complaint from an Ain’t it awful player will probably be very different from the way you handle a complaint from someone who isn’t playing that game. Just having that one extra strategy is likely to make a dramatic difference to your customer/client satisfaction ratings.
I’ve blogged here about how you can systematically map out the ways in which you can move an interaction from a given starting point. I’ve blogged here about the directions in which a plot can go; the same framework can be applied to TA life scripts.
Games are just one part of TA. There’s a bigger framework of TA theory beyond the games itself. That framework makes internal sense, and contains a lot of good points, but it would be stronger if it made more use of concepts from other areas. For brevity, I won’t try to describe or discuss the entire framework here, but I will give a couple of examples.
One is that TA games make better sense when combined with the concepts of expressive and instrumental behaviour, which I’ve blogged about here and here and here. Some TA games are purely expressive; others are both expressive and instrumental, in ways that have significant practical implications, as in the examples above from politics. For readers who are already familiar with TA, the concept of instrumental behaviour also meshes well with the TA concept of Adult within the TA division of interaction roles into Parent, Adult and Child.
Another is that a core concept within TA is how a person views themselves and others, with the options being OK and not OK; one of the classic TA books is called “I’m OK – You’re OK”. Although this is a useful insight, it’s limited to a binary choice. A much more powerful way of representing this is to use a two-axis scale, where you can plot how OK someone is on one axis, and how not OK they are on the other axis. We’ve blogged about this approach here and here.
There are plenty of other examples, such as linking TA games explicitly with script theory and schema theory.
So, in summary, Transactional Analysis contains some invaluable concepts and insights which deserve to be more widely known, and which are even more powerful when combined with complementary approaches from other fields.
Notes and links
You’re welcome to use Hyde & Rugg copyleft images for any non-commercial purpose, including lectures, provided that you state that they’re copyleft Hyde & Rugg.
There’s more about content analysis in my book with Marian Petre on research methods: Gordon Rugg & Marian Petre, A Gentle Guide to Research Methods
There’s more about the theory behind this article in my book Blind Spot, by Gordon Rugg with Joseph D’Agnese.
You might also find our website useful.
Gordon Rugg's Blog

- Gordon Rugg's profile
- 12 followers


{kind=link}
![[image error]](https://hydeandrugg.files.wordpress.com/2020/06/gladiators_from_the_zliten_mosaic_3.jpg){kind=link}