
David Dossot's Blog
February 9, 2015
Unveiling RxMule
I'm super excited to announce
RxMule
, my latest open source project. RxMule provides reactive extensions for Mule ESB, via a set of specific bindings for RxJava.

For several years, I've been mulling over the idea of creating a DSL for configuring Mule. Indeed, there is a treasure trove of pre-existing transports and connectors for Mule, which is very compelling for anyone building connected applications (which, nowadays, is probably everybody). Unfortunately developers can be put off by the XML-based DSL used to configure Mule, and thus may pass the opportunity to leverage all this available goodness.
As Rx is gaining traction, more and more developers are getting accustomed to its concepts and primitives. With this mind, and knowing that Mule is at core an event processing platform, it dawned on me that instead of creating a DSL that would mimic the XML artifacts (which are Mule specific), I'd rather create bindings to allow using Mule's essential moving parts via Rx.
In summary, RxMule adds a number of classes to RxJava that make it possible to observe:
Mule inbound endpoints from traditional transports, including global endpoints and endpoints defined by URIs,raw message sources, like the new HTTP Listener Connector,Anypoint Connectors message sources.In short, RxMule allows creating Observable<MuleEvent> instances from different sources. A MuleEvent is what Mule creates and processes. It wraps a MuleMessage which contains the actual data and meta-data that's being processed.
So why don't you take RxMule for a spin and see if it helps you achieving your application and API integration needs: with Mule at its core, I bet it will! Bug reports and pull requests are welcome at GitHub.
For several years, I've been mulling over the idea of creating a DSL for configuring Mule. Indeed, there is a treasure trove of pre-existing transports and connectors for Mule, which is very compelling for anyone building connected applications (which, nowadays, is probably everybody). Unfortunately developers can be put off by the XML-based DSL used to configure Mule, and thus may pass the opportunity to leverage all this available goodness.
As Rx is gaining traction, more and more developers are getting accustomed to its concepts and primitives. With this mind, and knowing that Mule is at core an event processing platform, it dawned on me that instead of creating a DSL that would mimic the XML artifacts (which are Mule specific), I'd rather create bindings to allow using Mule's essential moving parts via Rx.
In summary, RxMule adds a number of classes to RxJava that make it possible to observe:
Mule inbound endpoints from traditional transports, including global endpoints and endpoints defined by URIs,raw message sources, like the new HTTP Listener Connector,Anypoint Connectors message sources.In short, RxMule allows creating Observable<MuleEvent> instances from different sources. A MuleEvent is what Mule creates and processes. It wraps a MuleMessage which contains the actual data and meta-data that's being processed.
You can read more about the structure of a MuleMessage here.The following demonstrates an asynchronous HTTP-to-Redis bridge, that only accepts one request per remote IP:
So why don't you take RxMule for a spin and see if it helps you achieving your application and API integration needs: with Mule at its core, I bet it will! Bug reports and pull requests are welcome at GitHub.


November 15, 2014
Call me never (Ignite Talk)
I've been super honoured to give an ignite talk during DevOps Days Vancouver 2014. Ignite talks are intense, as the slides mercilessly fly-by every 15 seconds, and this for 5 minutes sharp (yes, that's just 20 slides!).


In this talk, I tried to present some of the lessons we've learned at Unbounce while rebuilding our page serving infrastructure. Our availability target is five-nines (that's an allowance of 6 seconds of downtime per week) so we've put lots of effort into building a stable, self-healing, gracefully-degrading piece of software. We had a few close calls though, hence the lessons learned shared in this talk.


I was initially planning to cover this subject in a 30 minutes talk and had gathered tons of material to go in-depth, so delivering this material in 5 minutes was an interesting challenge! It was good actually, as it forced me to be drastically concise, while trying to preserve interesting content.
If you can put up with my French accent, you can watch the recorded presentation here:
Otherwise, here are the slides:


In this talk, I tried to present some of the lessons we've learned at Unbounce while rebuilding our page serving infrastructure. Our availability target is five-nines (that's an allowance of 6 seconds of downtime per week) so we've put lots of effort into building a stable, self-healing, gracefully-degrading piece of software. We had a few close calls though, hence the lessons learned shared in this talk.


I was initially planning to cover this subject in a 30 minutes talk and had gathered tons of material to go in-depth, so delivering this material in 5 minutes was an interesting challenge! It was good actually, as it forced me to be drastically concise, while trying to preserve interesting content.
If you can put up with my French accent, you can watch the recorded presentation here:
Otherwise, here are the slides:
November 5, 2014
yopa is (almost) Your Own Personal AWS
If you're using AWS SQS and SNS for more than trivial things, you've probably wished that you could run your queues and topics locally, and be able to peek at the message flows happening in topics subscriptions.

Enter yopa , a local SQS and SNS simulator whose sole purpose in life is to make developers' lives easier! Open sourced by Unbounce and coded in Clojure by yours truly, yopa builds on the solid foundation of ElasticMQ and adds its own SNS implementation.
Granted, yopa only supports SQS and SNS for now so it's light years away from truly being Your Own Personal AWS but, hey, let's start small and see where it goes. And actually, there are already discussions about adding support for some EC2 and S3 APIs features as well.
So if you're using SQS and SNS, please give yopa a try! Pull requests are more than welcome.
PS. Oh, there's also a Docker image available...

Enter yopa , a local SQS and SNS simulator whose sole purpose in life is to make developers' lives easier! Open sourced by Unbounce and coded in Clojure by yours truly, yopa builds on the solid foundation of ElasticMQ and adds its own SNS implementation.
Granted, yopa only supports SQS and SNS for now so it's light years away from truly being Your Own Personal AWS but, hey, let's start small and see where it goes. And actually, there are already discussions about adding support for some EC2 and S3 APIs features as well.
So if you're using SQS and SNS, please give yopa a try! Pull requests are more than welcome.
PS. Oh, there's also a Docker image available...
April 5, 2014
I write only about funny animals
The rabbit is out of the hat: I'm indeed working on a new book. It's called "
RabbitMQ Essentials
" and is published by PackT Publishing. Yes, you're reading right, after Mule, it's now RabbitMQ's turn! Clearly, I'm specializing in writing about animal-named technologies.
 (C) Kallisto Stuffed Animals
(C) Kallisto Stuffed Animals
Why writing yet another book about RabbitMQ? After all, there are already several very excellent books on the subject out there. I think Ross Mason gave the best answer to this question on Twitter:
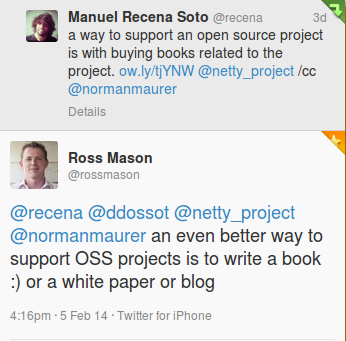
Let me further articulate the reasons why I decided to embark on this new book project while the ink on Mule in Action is still wet:
RabbitMQ is a great piece of open source technology and I think it can use all the coverage it can get. From the get go, RabbitMQ has been built with the idea to make things right: it's a breeze to install and configure. Adding extra plug-ins is a no-brainer. It's enterprise-grade software without the enterprise kludge. Moreover, AMQP is one of the rare messaging protocol that is truly interoperable so it too deserves to be discussed again and again.It's 2014 and surprisingly many developers still don't have a good grasp of messaging concepts. Beyond covering RabbitMQ, I'm covering more general principles around building distributed applications that leverage messaging as a decoupling agent. In the book, I'm sharing the love for everything asynchronous!I love to write not only code but about coding as well. I'm not an outdoor person by any stretch of imagination, so this new book is a perfect project for the gloomy and wet winter that we get in the Pacific North-West.The book will be short and easy to read. Its style will be conversational, with lots of questions asked to the reader. It won't be an in-depth coverage of any particular feature of RabbitMQ but will instead give a broad coverage of the broker, the AMQP protocol and some of the custom extensions added to it. The book will contain lots of code (Java, Ruby, Python) and will be articulated about the coding journey of a fictitious company that starts using RabbitMQ and see it multiply... and multiply...
Hopefully you'll enjoy this journey too and will learn a few things while reading RabbitMQ Essentials. You can pre-order your copy right from PackT's website.
Now what could be the next animal I could write about?
 (C) Kallisto Stuffed Animals
(C) Kallisto Stuffed AnimalsWhy writing yet another book about RabbitMQ? After all, there are already several very excellent books on the subject out there. I think Ross Mason gave the best answer to this question on Twitter:
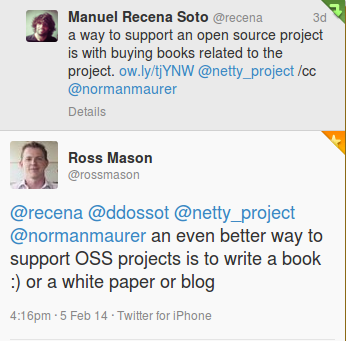
Let me further articulate the reasons why I decided to embark on this new book project while the ink on Mule in Action is still wet:
RabbitMQ is a great piece of open source technology and I think it can use all the coverage it can get. From the get go, RabbitMQ has been built with the idea to make things right: it's a breeze to install and configure. Adding extra plug-ins is a no-brainer. It's enterprise-grade software without the enterprise kludge. Moreover, AMQP is one of the rare messaging protocol that is truly interoperable so it too deserves to be discussed again and again.It's 2014 and surprisingly many developers still don't have a good grasp of messaging concepts. Beyond covering RabbitMQ, I'm covering more general principles around building distributed applications that leverage messaging as a decoupling agent. In the book, I'm sharing the love for everything asynchronous!I love to write not only code but about coding as well. I'm not an outdoor person by any stretch of imagination, so this new book is a perfect project for the gloomy and wet winter that we get in the Pacific North-West.The book will be short and easy to read. Its style will be conversational, with lots of questions asked to the reader. It won't be an in-depth coverage of any particular feature of RabbitMQ but will instead give a broad coverage of the broker, the AMQP protocol and some of the custom extensions added to it. The book will contain lots of code (Java, Ruby, Python) and will be articulated about the coding journey of a fictitious company that starts using RabbitMQ and see it multiply... and multiply...
Hopefully you'll enjoy this journey too and will learn a few things while reading RabbitMQ Essentials. You can pre-order your copy right from PackT's website.
Now what could be the next animal I could write about?
March 1, 2014
Explicit content required
I had this post in gestation for a while but the recent post on SmartBear's blog ("Please stop saying Java sucks") decided it me to finalize and publish it.
I believe that it's a complete fallacy to equate "less code" with "better", this whether one is considering a language or a framework. In that matter (like in many others), I think the Zen of Python provides the correct viewpoint:
I'm inclined to add that not having any code to read at all hinders the capacity to reason about a piece of software, hence reduces the ability to work with it.
One could brush aside this argument and argue that if a programmer knew better language X or framework Y, he or she should now that this or that behaviour would implicitly apply in the considered context. I would then posit that readability trumps knowledge.
Applications tend to last longer than fashionable tools, languages or frameworks. Long after the knowledge of the intimate details of whatever technology has been deemed useless and dumped into oblivion, someone will have to read the code and maintain it. This someone will appreciate to have the capacity to navigate all the aspects of the application by following explicit seams that bind them together.
When everything is implicit, an application code ends up like a novel where important points are pushed to footnotes, but without any reference to these footnotes. In that respect, I find Scala's implicits to be emblematic of a good approach to make code disappear and this because these implicits need to be explicitly used.
Coming back to SmartBear's post, old Java's code signal to noise ratio is the key problem. Things are getting better release after release: noise is decreasing and thus the ratio improves.
And that's the whole point of this post: throwing away the signal with the noise is not the solution. Code needs to be explicit so we can reason about it and so we can evolve it with confidence.
I believe that it's a complete fallacy to equate "less code" with "better", this whether one is considering a language or a framework. In that matter (like in many others), I think the Zen of Python provides the correct viewpoint:
Explicit is better than implicitWhy is this important? Here is a quote from Bob Martin's Clean Code:
The ratio of time spent reading (code) versus writing is well over 10 to 1 ... (therefore) making it easy to read makes it easier to write.
I'm inclined to add that not having any code to read at all hinders the capacity to reason about a piece of software, hence reduces the ability to work with it.
One could brush aside this argument and argue that if a programmer knew better language X or framework Y, he or she should now that this or that behaviour would implicitly apply in the considered context. I would then posit that readability trumps knowledge.
Applications tend to last longer than fashionable tools, languages or frameworks. Long after the knowledge of the intimate details of whatever technology has been deemed useless and dumped into oblivion, someone will have to read the code and maintain it. This someone will appreciate to have the capacity to navigate all the aspects of the application by following explicit seams that bind them together.
When everything is implicit, an application code ends up like a novel where important points are pushed to footnotes, but without any reference to these footnotes. In that respect, I find Scala's implicits to be emblematic of a good approach to make code disappear and this because these implicits need to be explicitly used.
Coming back to SmartBear's post, old Java's code signal to noise ratio is the key problem. Things are getting better release after release: noise is decreasing and thus the ratio improves.
And that's the whole point of this post: throwing away the signal with the noise is not the solution. Code needs to be explicit so we can reason about it and so we can evolve it with confidence.
November 23, 2013
More than a language
Nearly 300 high-level programming languages have been developed during the last decade.One can only nod when reading this quote: indeed there's hardly a month without a new language being announced. The fun part is that it's the opening sentence of "A Guide to PL/I", printed in 1969! Clearly the programming community has always been prolific when it comes to spawning languages.
And this trend makes sense: the tension between the need for general programming languages, which can deal with any type of problems, and the desire for specific programming languages, which best accommodate particular issues, is prone to give birth to a wide range of diverse languages.
As a programmer, you therefore have plenty of choice when it comes to picking up a language for your shiny new project. Beyond the intrinsic qualities of the language, I posit that there's more to consider when deciding. Here are a few points that come to mind:
Platform - What is the runtime environment that this languages runs on? Is it mature? Is it easy to install and upgrade? Can it be well monitored in production? Does it use system resources efficiently?Ecosystem - Is there a large body of libraries available? Are these libraries mature? Does the community have a tradition for rolling out breaking changes in libraries?Tooling - Are there any tools for crafting code with this language? Any auto-formatters so SCM conflicts are minimal? Any static analysis tools? Any dynamic analysis tools?I haven't included the "availability of developers" criteria because I think it's a red herring. Indeed, I'm convinced any programmer worth hiring should be able to pick up a new language very quickly.
So if your project can accommodate risk and potential yak shaving, you can disregard these points and select a language only for itself. But for those building systems that should last and evolve gracefully, these extra criteria should be considered as much as the qualities of the language itself.
Are there any other aspects you typically consider when opting for a particular language that you'd like to share?
April 26, 2013
Meet jerg, a JSON Schema to Erlang Records Generator
I'm happy to announce the very first release of my latest Erlang open source project, jerg, a JSON Schema to Erlang Records Generator.
The objective of this project is to be a build tool that parses a rich domain model defined in JSON Schema (as specified in the IETF Internet Draft) in order to generate record definitions that can be used to Erlang applications to both read and write JSON.
I believe that having a formally defined object model for the data that's exchange over web resources is a major plus for APIs. It doesn't necessary imply that consumers have to generate static clients based on such a definition, but as far as the server is concerned, it raises the bar in term of consistency and opens the door for self-generated documentation.
jerg doesn't deal with the actual mapping between JSON and records: there is already a library named json_rec for that. It doesn't also deal with validation as, again, a library named jesse can take care of it.
This first version of jerg generates records with the appropriate type specification to enable type checking with dialyzer. It supports:
cross-references for properties and collection items (ie the $ref property),default values,integer enumerations (other types can not be enumerated per limitation of the Erlang type specification).It also supports a few extensions to JSON schema:extends: to allow a schema to extend another one in order to inherit all the properties of its parent (and any ancestors above it),abstract: to mark schemas that actually do not need to be output as records because they are just used through references and extension,recordName: to customize the name of the record generated from the concerned schema definition.jerg has a few limitations, like its lack of support for embedded object schemas: pull-requests are more than welcome!
Enough talking: time to get started! Your next stop is jerg's GitHub project. Enjoy!
The objective of this project is to be a build tool that parses a rich domain model defined in JSON Schema (as specified in the IETF Internet Draft) in order to generate record definitions that can be used to Erlang applications to both read and write JSON.
I believe that having a formally defined object model for the data that's exchange over web resources is a major plus for APIs. It doesn't necessary imply that consumers have to generate static clients based on such a definition, but as far as the server is concerned, it raises the bar in term of consistency and opens the door for self-generated documentation.
jerg doesn't deal with the actual mapping between JSON and records: there is already a library named json_rec for that. It doesn't also deal with validation as, again, a library named jesse can take care of it.
This first version of jerg generates records with the appropriate type specification to enable type checking with dialyzer. It supports:
cross-references for properties and collection items (ie the $ref property),default values,integer enumerations (other types can not be enumerated per limitation of the Erlang type specification).It also supports a few extensions to JSON schema:extends: to allow a schema to extend another one in order to inherit all the properties of its parent (and any ancestors above it),abstract: to mark schemas that actually do not need to be output as records because they are just used through references and extension,recordName: to customize the name of the record generated from the concerned schema definition.jerg has a few limitations, like its lack of support for embedded object schemas: pull-requests are more than welcome!
Enough talking: time to get started! Your next stop is jerg's GitHub project. Enjoy!
February 16, 2013
CRaSH for Mule, an introduction
This blog is the formal introduction to the CRaSH console for Mule on which I've been working for the past month or so. I've decided to interview myself about it because, hey, if I don't do it, who will?

What is CRaSH for Mule?It is a shell that is running embedded in Mule and that gives command-line access to a variety of Mule internal moving parts. It's built thanks to the excellent CRaSH project, a toolkit built by Julien Viet and sponsored by eXo Platform, which allows the easy creation of embedded shells.
What can we do with it?Well, it's easy to find it out. Let's connect to CRaSH for Mule and ask for help:
As you can see the range of actions include gathering information, like statistics and names, but also performing actions, like restarting a connector or even stopping the broker.
Why is it better than JMX?Behind the scene CRaSH for Mule relies on JMX so anything you can do with it could be done with direct JMX interactions (like with JConsole or jmxterm). This said CRaSH for Mule has many advantages over raw JMX, including:
Adds Mule semantics to JMX. You do not need to fiddle with lengthy object names do achieve what you want: CRaSH for Mule builds the right object names based on your actions.Provides auto-completion, this for application names and commands.Supports connectivity over telnet and ssh. No need for baroque JMX RMI connection strings.All the other CRaSH commands are available. The default set of commands is very rich: to name a few, it comes complete with commands for dealing with the system, the JVM, JDBC and JNDI.
How does it compare to MMC?Well, it doesn't! The Mule Management Console is way more capable and feature-laden, and comes bundled with the Enterprise Edition of Mule.
CRaSH for Mule focuses on admin-oriented command-line friendly interactions with Mule. And it is fully open sourced.
How do I install it?Navigate to CRaSH's homepage and locate the Mule distribution download link. You'll get an archive that contains different files, including crash-mule-app.zip that you need to drop in your Mule broker apps directory. This application contains a readme file that explains how to configure it, should the default configuration not satisfy you. You can also read it online.
CRaSH for Mule 1.2.0-cr6-SNAPSHOT has been tested on Mule CE 3.3.1 and EE 3.3.1.
Got into trouble?Report issues or open feature requests directly to CRaSH's JIRA.
December 27, 2012
My Final Word (Almost)
In "Final Parameters and Local Variables", Dr. Heinz M. Kabutz rants against the generalized used of the final keyword in Java code. For him, this is a "trend' and an "idiotic coding standard".
I'm a firm believer of the complete opposite.
As a software developer, I spend most of my time reasoning about code. Anything that can make this reasoning easier is welcome. Good practices like short methods and descriptive names fall in this category. I believe immutable variables do too.
Immutable variables simplify reasoning because they ensure a stable state within a scope, whether it's a whole class or a single method. Having established invariants is a tremendous help in understanding code.
Whether it is with my own code or not, I've experienced time and again that my mental load was way lower with immutable variables than mutable ones. Maybe it's just a limitation of my own brain power, but, to me, less mental load translates in deeper understanding. And to the contrary, finding out amid-function that one of its argument has been reassigned creates an intense sense of confusion, prompting to re-read the method again. And again.
Of course, this isn't 100% true in Java, mainly because its default data structures are unfortunately mutable. But still, the comfort gained by using the final keyword everywhere, and actually letting your favourite IDE do it for you, far outweighs the small visual clutter it creates.
Dr. Kabutz will certainly argue that this is a matter of personal discipline or talent to ensure that one doesn't mess with invariants, because he doesn't "need the compiler to tell [him] this". Again I disagree. I don't trust myself to be on top of things at all time so I want the compiler to tell me everything... and more. I want Findbugs to scrutinize everything I write and break the build if I've been sloppy. I want Checkstyle to reject my code if it isn't compliant to whatever standard is enforced on the project I'm working on.
I do agree on one thing that Dr. Kabutz said though, which is that using the final keyword everywhere in printed books' code snippets is an annoyance. Indeed, books formatting rules constraints on code samples are so stringent (think 71 columns) that the rules of readability are tipped towards "less code as possible".
What is your experience with final variables everywhere? Love, hate or ...
I'm a firm believer of the complete opposite.
As a software developer, I spend most of my time reasoning about code. Anything that can make this reasoning easier is welcome. Good practices like short methods and descriptive names fall in this category. I believe immutable variables do too.
Immutable variables simplify reasoning because they ensure a stable state within a scope, whether it's a whole class or a single method. Having established invariants is a tremendous help in understanding code.
Whether it is with my own code or not, I've experienced time and again that my mental load was way lower with immutable variables than mutable ones. Maybe it's just a limitation of my own brain power, but, to me, less mental load translates in deeper understanding. And to the contrary, finding out amid-function that one of its argument has been reassigned creates an intense sense of confusion, prompting to re-read the method again. And again.
Of course, this isn't 100% true in Java, mainly because its default data structures are unfortunately mutable. But still, the comfort gained by using the final keyword everywhere, and actually letting your favourite IDE do it for you, far outweighs the small visual clutter it creates.
Unsurprisingly, I'm of the same opinion about early returns and loop breaks, but this is for another debate...
Dr. Kabutz will certainly argue that this is a matter of personal discipline or talent to ensure that one doesn't mess with invariants, because he doesn't "need the compiler to tell [him] this". Again I disagree. I don't trust myself to be on top of things at all time so I want the compiler to tell me everything... and more. I want Findbugs to scrutinize everything I write and break the build if I've been sloppy. I want Checkstyle to reject my code if it isn't compliant to whatever standard is enforced on the project I'm working on.
I do agree on one thing that Dr. Kabutz said though, which is that using the final keyword everywhere in printed books' code snippets is an annoyance. Indeed, books formatting rules constraints on code samples are so stringent (think 71 columns) that the rules of readability are tipped towards "less code as possible".
What is your experience with final variables everywhere? Love, hate or ...
April 21, 2012
IDlight Launched!
I'm super excited to announce the launch of IDlight, my very first SaaS. I'll promote it further after the week-end, but I wanted my blog readers to be the first to know :)

IDlight is an API that allows applications to retrieve public profile information. Among other things, it uses established and emerging standards like Webfinger, XRD and hCard to retrieve and parse public profiles.
It unifies all the retrieved data under a unique schema, which makes it easy for applications to consume in a consistent manner.
Please give it a try and share your feedback directly on idlight.net.
IDlight is an API that allows applications to retrieve public profile information. Among other things, it uses established and emerging standards like Webfinger, XRD and hCard to retrieve and parse public profiles.
It unifies all the retrieved data under a unique schema, which makes it easy for applications to consume in a consistent manner.
Please give it a try and share your feedback directly on idlight.net.


